

“El mejor sitio en Internet para esconder un cadáver es la segunda página de resultados de Google”.
Leí esta frase hace algún tiempo y me causó mucha gracia, sobre todo porque en la mayoría de las búsquedas que hacemos nos limitamos a los primeros 5 o 7 resultados. De hecho… ¿cuándo fue la última vez que llegaste a buscar en la segunda página?
La mayoría de las personas que utilizan este buscador jamás pasan de la primera hoja, ya que, gracias a los servicios inteligentes de indexación y posicionamiento, habitualmente la información que necesitan aparece dentro de los primeros resultados.
Sin embargo, si alguna vez has necesitado buscar información específica sobre algún tema “poco convencional”, es posible que hayas revisado hasta la tercera página, muchas veces incluso con la frustración de no encontrar los resultados esperados…
Imagen obtenida de emezeta.com
Lo que muchos no saben es que este buscador posee algunas simples instrucciones que permiten parametrizar nuestras búsquedas para obtener información que habitualmente no llegaría a aparecer. Es decir, con solo cambiar la forma en la que preguntamos podemos obtener resultados mucho más precisos; y para esto, solo necesitamos saber utilizar los operadores avanzados de búsqueda de Google.
Varios de estos operadores son conocidos y mucha gente los utiliza a diario sin darse cuenta. Entre los más comunes tenemos: las comillas (“”) para buscar el texto exacto, el comodín (*) para completar una frase o el ya obsoleto signo suma (+) para concatenar palabras. Además de estos operadores, existen otros no tan conocidos pero muy útiles, por ejemplo, ‘OR’ (|), que busca resultados que contengan cualquiera de las palabras; el signo menos (-), que se utiliza para excluir palabras de la búsqueda; o los dos puntos consecutivos (..) para indicar un rango de números.
También existen otros operadores cuyo uso es menos frecuente, pero que resultan sumamente útiles si necesitamos acotar nuestra búsqueda. Estos son:
- Intitle: busca en el título de la página
- inurl: busca en la URL de la página
- intext: busca en el texto de la página y excluye los títulos y URL
- site: busca solo dentro del sitio o dominio especificado luego de “site:”
- link: busca en páginas que tienen un link a un sitio determinado
- filetype: busca archivos del tipo especificado (doc, xls, txt, etc.)
- inanchor: busca en el texto de un link, es decir, páginas en cuyos enlaces aparezca el termino buscado.
- cache: busca en el cache de Google, se utiliza para buscar información anterior
- related: busca webs relacionadas a la web buscada
- info: muestra información sobre la indexación en Google del sitio.
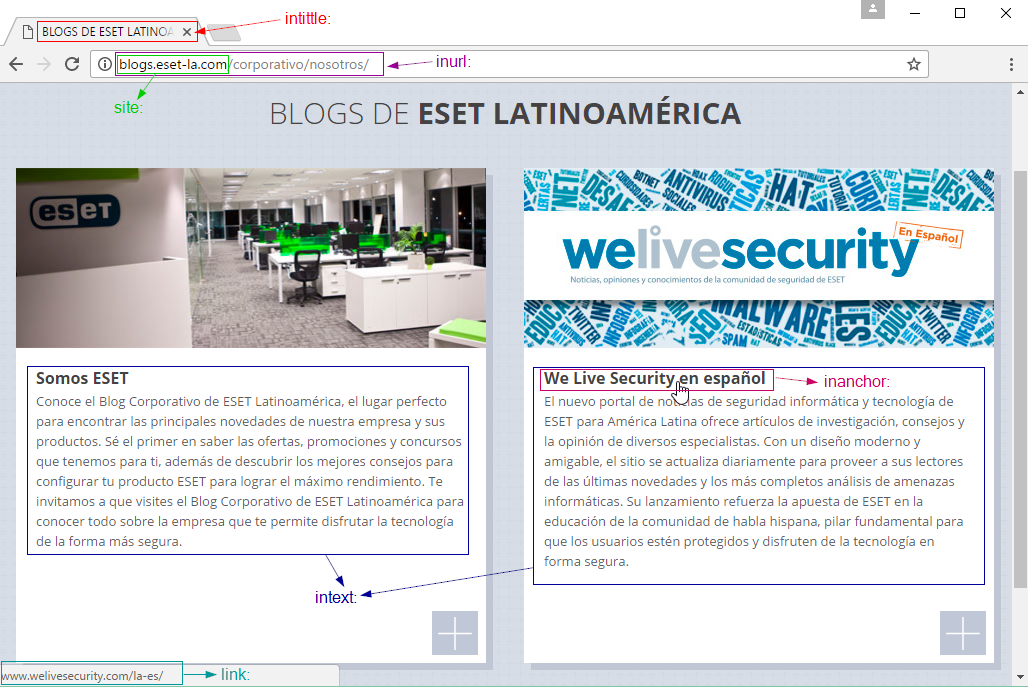
Para que entendamos mejor estos operadores, veamos en la siguiente imagen dónde se encuentran las palabras claves que utiliza cada uno:
Ahora, ¿qué pasa si juntamos todo esto?
Digamos, por ejemplo, que quiero buscar archivos, imágenes y documentos que diferentes personas hayan subido a la nube. Se me ocurre la siguiente búsqueda:
"My Documents" .jpg intitle:index.of
Utilizando estos operadores le indico a Google: búscame las palabas textuales ‘My Documents’ y la extensión .jpg en páginas cuyo título contenga ‘Index of’. La razón por la que filtro las webs por el título ‘Index of’ se debe a que, por defecto, la mayoría de los servidores web listan sus directorios y archivos con este título. Si el administrador de la página no presta atención a esta configuración, el buscador habrá indexado todos sus directorios públicos y aparecerán en los resultados.
Veamos qué obtuvimos:
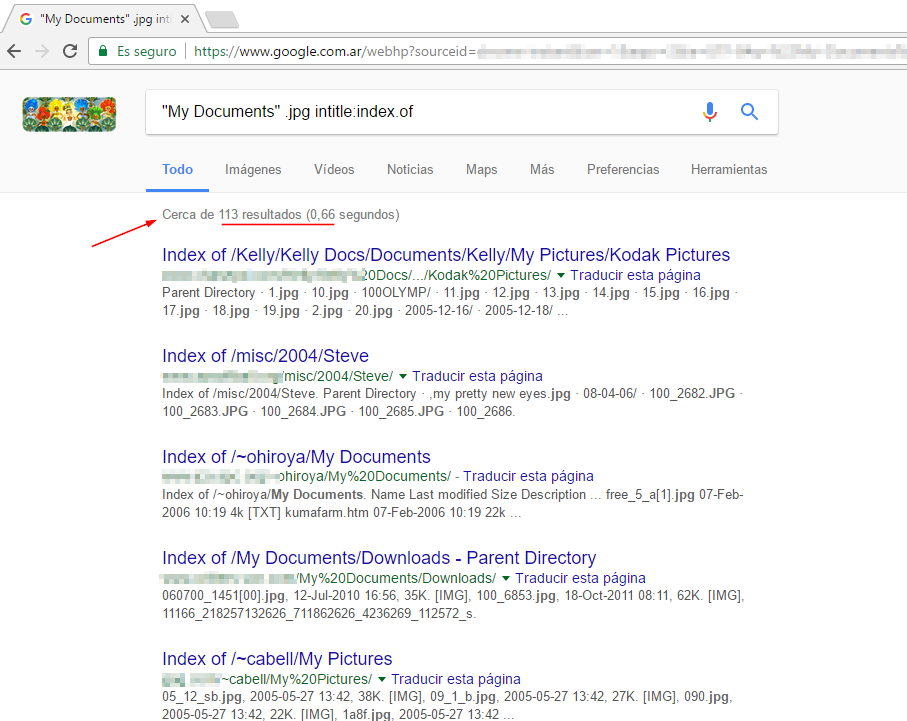
Al parecer, encontramos más de 100 sitios con sus directorios indexados y que contienen fotos y documentos de diferentes personas. Veamos qué tipo de documentos están publicados:
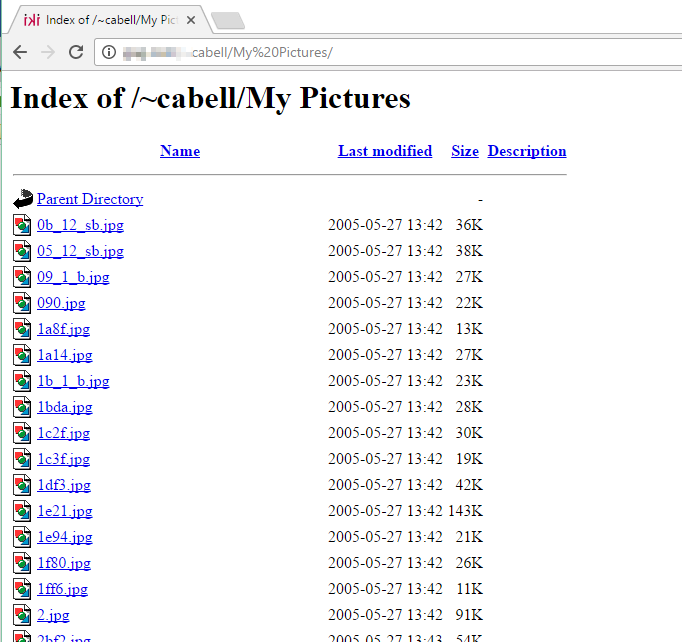
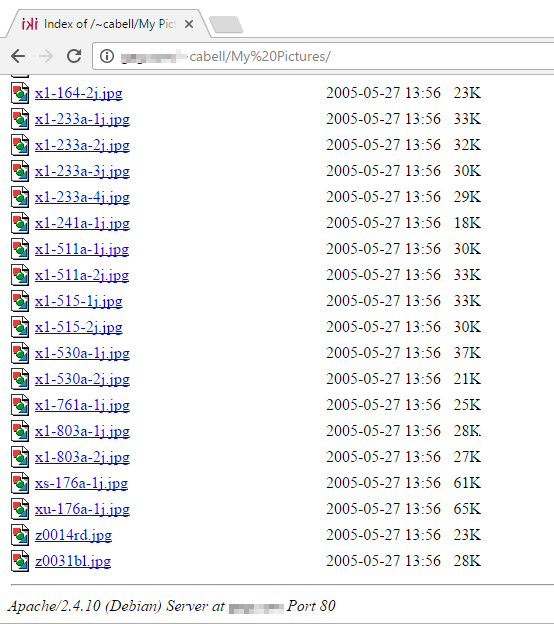
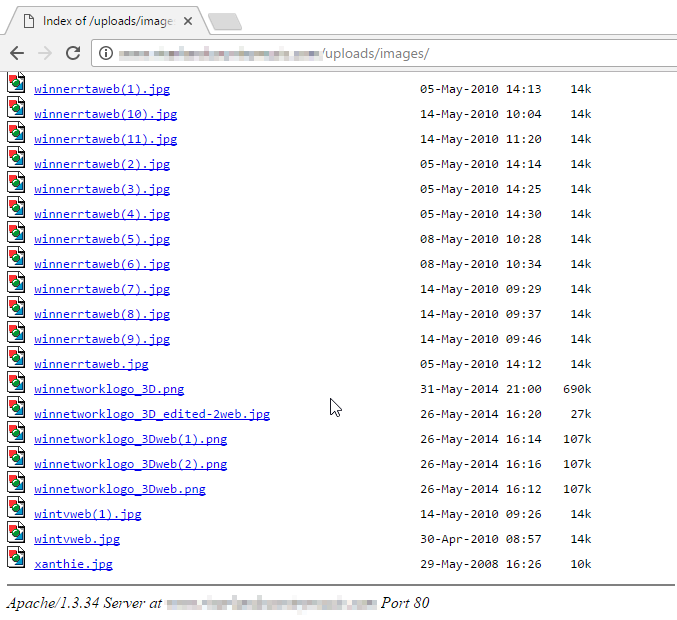
Estos sitios tienen varias fotos y documentos personales que se pueden descargar sin ningún problema, y además, varios todavía utilizan versiones vulnerables de Apache.
Si bien estos son simplemente ejemplos, imaginemos qué pasaría si estuviera buscando documentos de una empresa, el listado de empleados y correos electrónicos o incluso una base de datos completa. Podría quizá encontrarme cosas como esta:
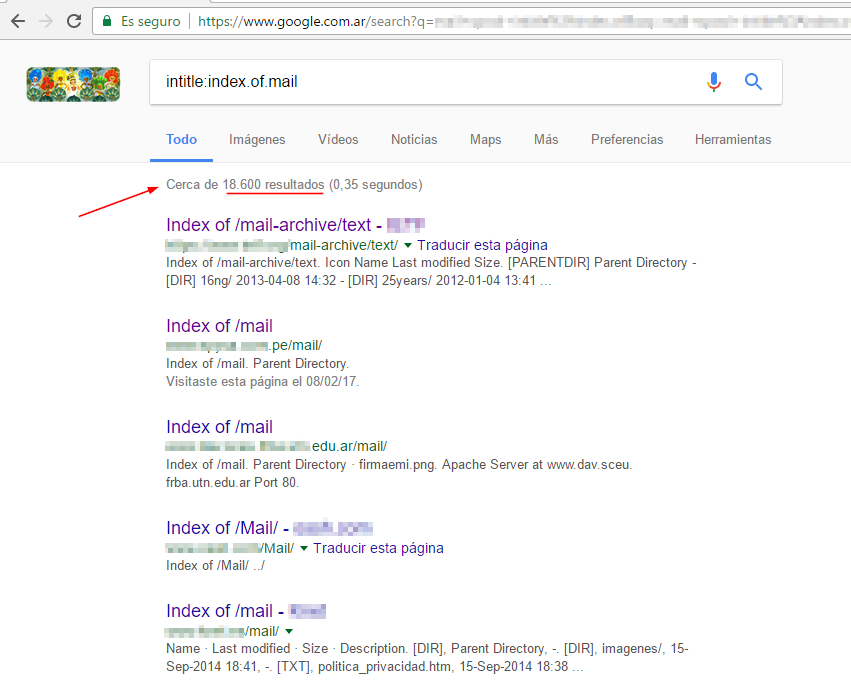
Miles de resultados con directorios de correos electrónicos archivados, de los cuales muchos están completamente accesibles:
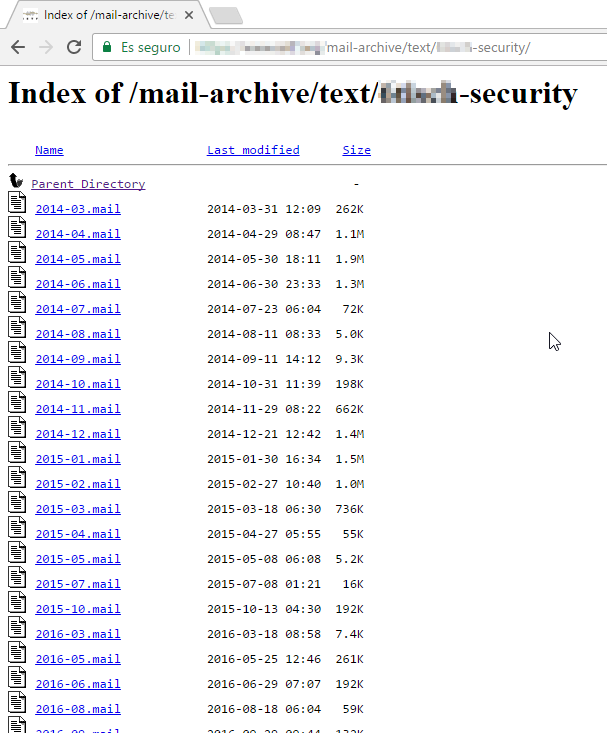
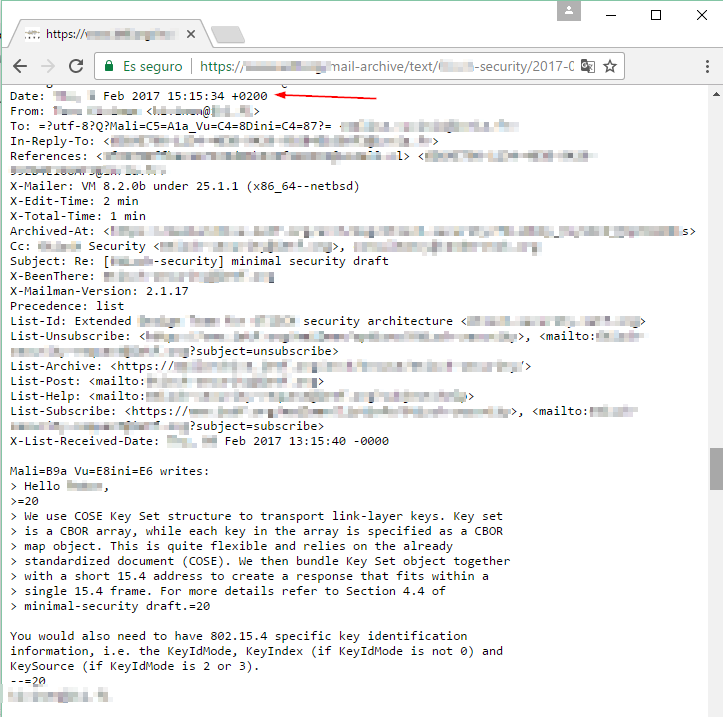
Utilizando estos operadores, podemos buscar también puertos y conexiones menos convencionales, como servicios FTP (para transferencia de archivos), puertos de conexión remota o incluso cámaras web y otros dispositivos publicados.
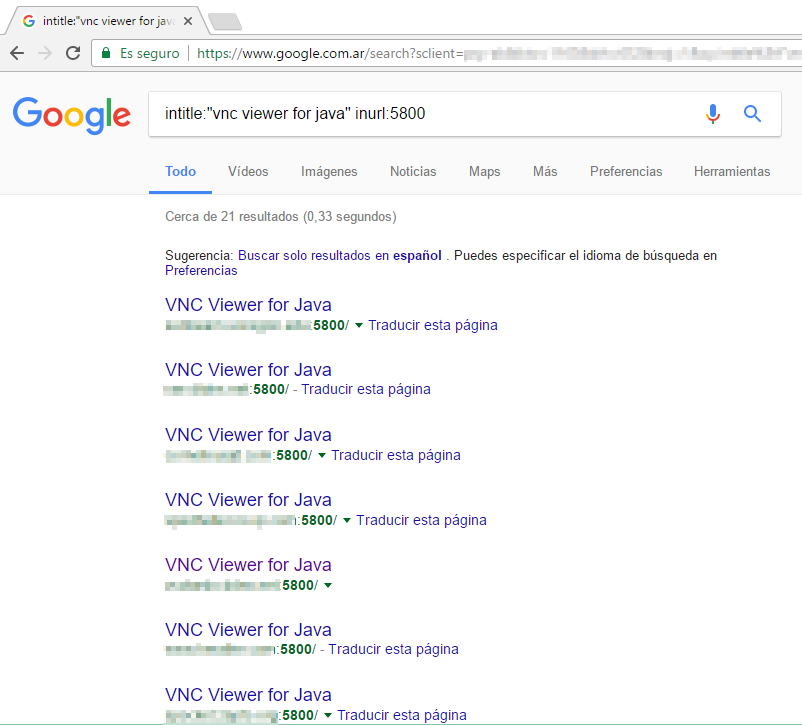
En el ejemplo anterior buscamos conexiones VNC, una conocida aplicación de administración remota que corre por defecto en el puerto 5800. Por suerte, solo obtuvimos 21 resultados en 33 segundos, ya que esta aplicación cuenta con varias vulnerabilidades conocidas.
De manera similar, ¿podría algún curioso obtener usuarios y claves publicados?
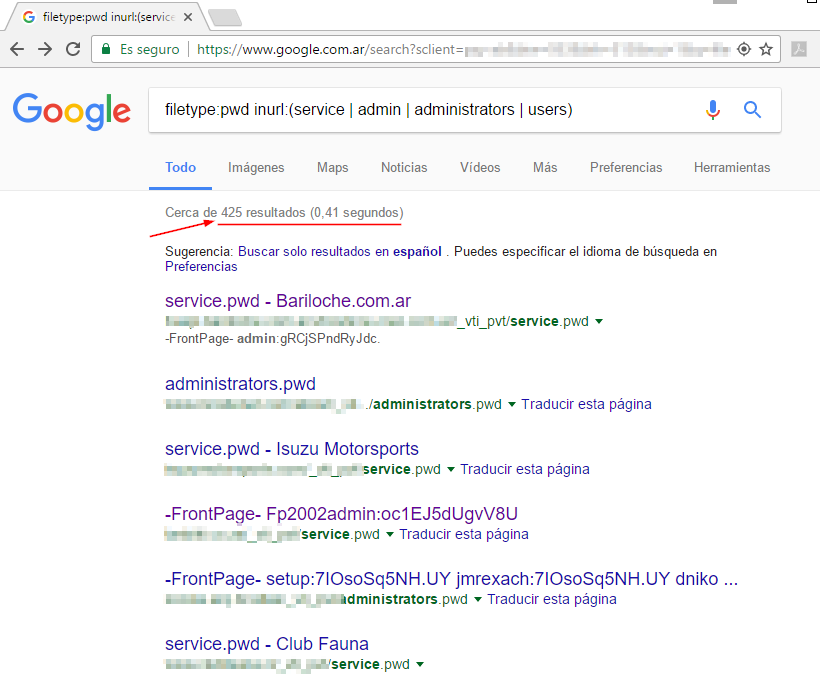
Vemos en este ejemplo que, buscando archivos del tipo “pwd” (archivo habitual de credenciales) en URL que contengan las palabras ‘admin’, ‘service’ o ‘users’ (que generalmente se utilizan para administrar las páginas), aparecen más de 300 ficheros con usuarios y claves, muchos de ellos con esta información sensible directamente visible desde el buscador.
El objetivo de este artículo no es revelar información sensible sino concientizar acerca de la información que se encuentra publicada en Internet y la importancia de revisar tanto la configuración de los servicios publicados como la indexación de los mismos en los buscadores.
Es por eso que te invito a buscar tu nombre, tu empresa y cualquier otro tipo de información sensible utilizando los diferentes operadores de búsqueda y mirando más allá de la segunda página de resultados.
Por último, te invito a buscar los términos ‘do a barrel roll’ en el cuadro de búsquedas principal o ‘atari breakout’ en la búsqueda por imágenes, y encontrarse con algunas sorpresas... esta vez, totalmente inofensivas y divertidas ;)



