

Hace unas semanas participé como oradora en el Blue Space de la conferencia EkoParty en Argentina, con una charla sobre los ataques a modelos de Machine Learning (ML) titulada “With Great Power Comes Great Responsibility: AML”. En esta oportunidad, y continuando con la temática, además de repasar cuáles pueden ser las consecuencias de un ataque a un sistema de ML, quiero compartir algunas herramientas de utilidad para mejorar la seguridad de estos modelos tomando como referencia la información publicada por el NIST.
Consecuencias de los ataques a un sistema de Machine Learning
En principio, es importante tener en cuenta que las consecuencias de un ataque a un modelo de ML están sujetas a las defensas implementadas en dicho sistema.
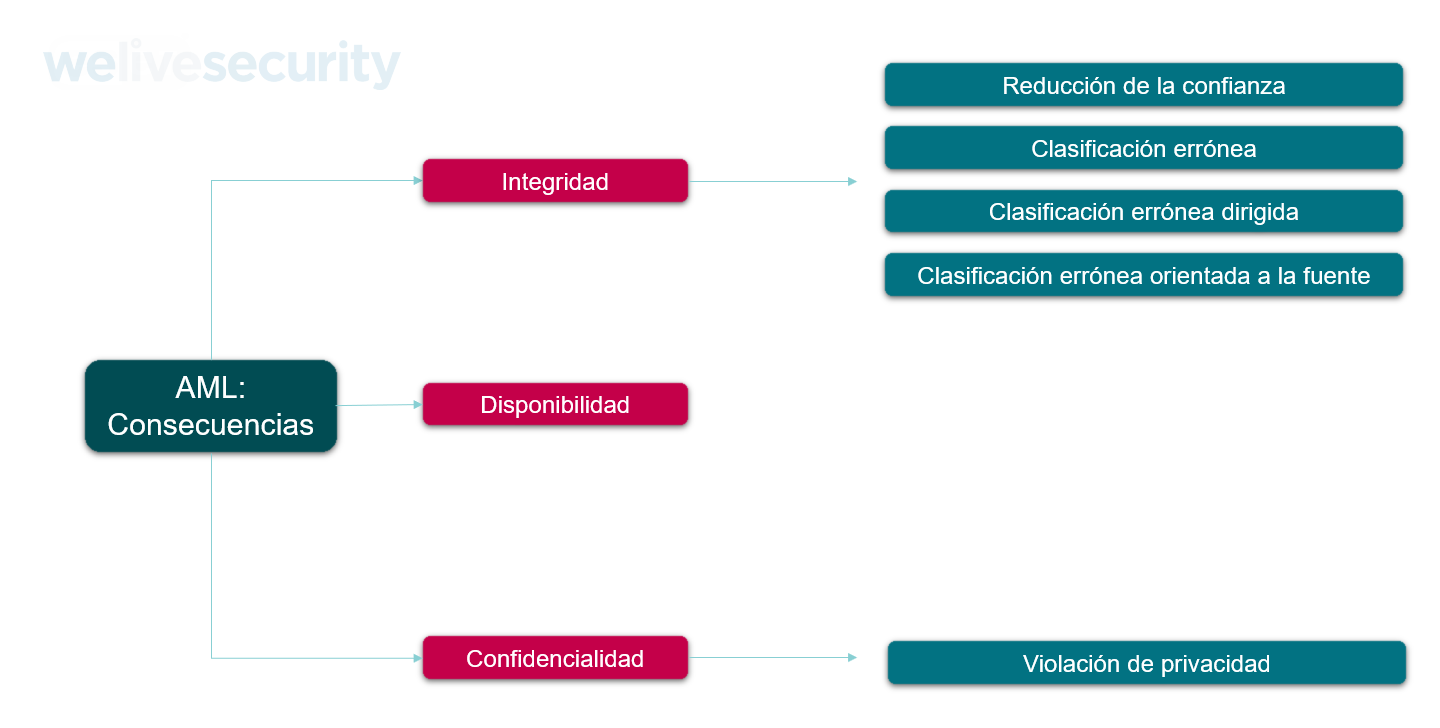
Imagen 1 - Consecuencias de ataque a ML según NIST
Aclarado esto, cuando se habla de las consecuencias de un incidente de seguridad, cualquier sea el mismo, tenemos que hablar de tres pilares de la seguridad: la confidencialidad, integridad, y disponibilidad (CID) de la información. A continuación, analizamos las consecuencias de un ataque a un modelo de ML para cada uno de estos pilares.
Integridad
Como vimos en el post “Adversarial Machine Learning: Introducción a los ataques a modelos de ML”, llegamos a la fase de “predicción” o “inferencia” luego de haber obtenido un modelo, aportarle un nuevo set de datos, y contar con un ML ya entrenado y capaz de “detectar” o hasta incluso “predecir”. Dicho esto, si analizamos las consecuencias desde la perspectiva de la integridad de la información, algunas consecuencias son:
- Reducción de la confianza:
Cuando la integridad del sistema de ML se ve afectado, se pierde confianza sobre la etapa de inferencia porque se puede producir una clasificación errónea en cualquier clase diferente de la original.
- Clasificación errónea y clasificación errónea dirigida:
Las clasificaciones erróneas más específicas incluyen a la clasificación errónea dirigida de entradas a una clase de salida de destino específica, y la clasificación errónea de origen-destino de una entrada específica a una clase de salida de destino específica.
En un modelo de ML del tipo no supervisado puede verse afectado su integridad cuando al introducir un nuevo dato, las características seleccionadas por ese modelo son incoherentes. Por otro lado, cuando hablamos en el aprendizaje por refuerzo la integridad se puede ver afectada cuando el modelo de ML no posee un buen rendimiento o hasta incluso las decisiones adoptadas por el algoritmos no son correctas.
Disponibilidad
Una violación a la disponibilidad de la información en un sistema de Machine Learning puede afectar tanto a la calidad —por ejemplo, que se vea afectada la velocidad de inferencia— como al acceso —por ejemplo, denegación de servicio— al punto de hacer que el componente ML no esté disponible para los usuarios.
Aunque un ataque que afecte a la disponibilidad de la información puede implicar reducciones de la confianza o clasificaciones erróneas similares a las de las infracciones de integridad, la diferencia es que las infracciones de disponibilidad dan como resultado una velocidad inaceptable o una denegación de acceso que inutilizan el resultado o la acción de un modelo.
Confidencialidad
Las violaciones a la confidencialidad de la información ocurren cuando un adversario extrae o infiere información sobre el modelo y los datos que utiliza. Los incidentes que afectan a la información confidencial de un modelo de Machine Learning incluyen ataques que revelan la arquitectura o los parámetros del mismo. Por su parte, los ataques que revelan información confidencial sobre los datos incluyen ataques de inversión. Estos últimos existen cuando un adversario explota el modelo de destino para recuperar datos faltantes utilizando entradas parcialmente conocidas.
Privacidad: Las violaciones a la privacidad de la información de un modelo de Machine Learning son una clase específica de violación a la confidencialidad en la que el adversario obtiene información personal sobre una o más entradas legítimas de modelos individuales. Un ejemplo sería cuando un adversario adquiere o extrae los registros médicos de un individuo violando las políticas de privacidad.
Herramientas para evaluar robustes de un sistema de IA/ML
Como mencioné en las secciones anteriores, las consecuencias de los ataques a modelos de ML son diversas. Esto llevó a varios grupos de desarrolladores e investigadores a buscar a través de diversas herramientas la forma de ayudar a mejorar la robustez de estos modelos antes de lanzarlos a producción.
A continuación, compartimos algunas de estas herramientas:
Adversarial Robustness ToolBox (ART)
Adversarial Robustness Toolbox (ART) es una biblioteca de Python que busca mejorar la seguridad de los modelos de Machine Learning. El objetivo principal de ART es brindar herramientas a los desarrolladores e investigadores para evaluar, defender, certificar y verificar modelos y aplicaciones de aprendizaje automático para evitar a las amenazas adversarias de evasión, envenenamiento, extracción e inferencia. En este sentido, a través de ART es posible evaluar la robustez desde una perspectiva de defensa (Blue Team) o de ataque (Red Team).
TrojanNet
Esta herramienta es una que muestra cómo es posible insertar un troyano en un modelo de Deep Learning de ML. Se trata de una propuesta que presentaron e investigadores de Texas A&M en el paper “An Embarrassingly Simple Approach for Trojan Attack in Deep Neural Networks”.
A través de TrojanNet se busca insertar un código malicioso en un pequeño módulo del modelo de destino. El modelo infectado podrá clasificar erróneamente las entradas en una etiqueta de destino cuando las entradas estén marcadas con activadores especiales. De esta manera, lo que se busca a través de esta pequeña modificación es activar determinadas neuronas para que el modelo clasifique de manera errónea.
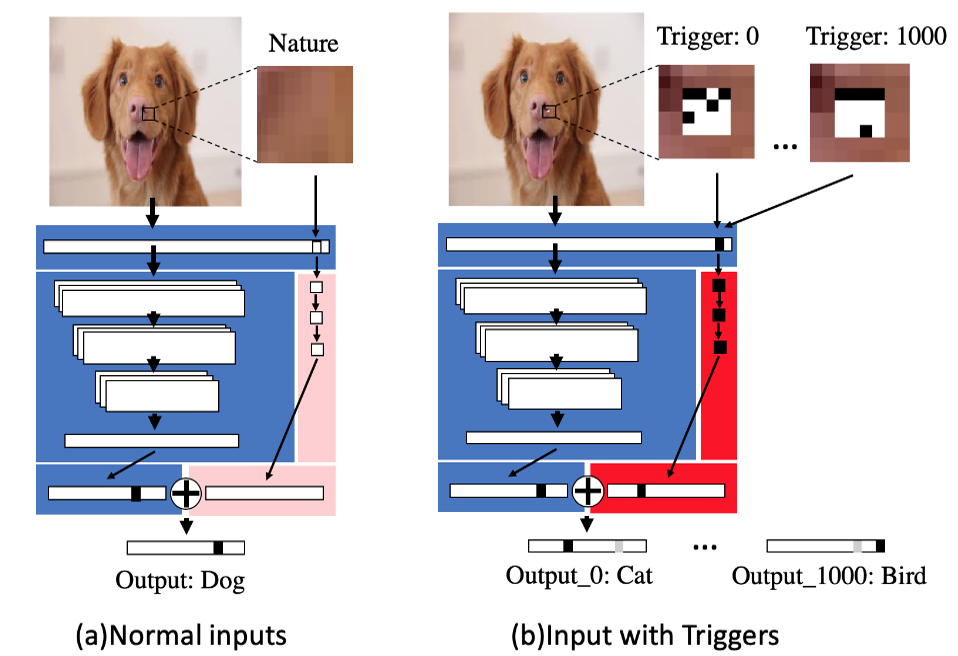
Fig. 3 - TrojanNet Ejemplo de utilización (Fuente: Github/TrojanNet)
CleverHands
CleverHands es una biblioteca desarrollada por el laboratorio CleverHands de la Universidad de Toronto que brinda una implementación de referencias de ataques contra modelos de aprendizaje automático para ayudar a comparar modelos con ejemplos contradictorios.
Advertorch
Advertorch es una biblioteca desarrollada en Python para evaluar la robustez de los modelos de ML implementados en PyTorch. A su vez contiene módulos para generar perturbaciones adversarias dentro de los modelos de ML, lo cual permite a los desarrolladores implementar modelos más seguros. Además, Advertorch ofrece scripts automatizados para el entrenamiento de adversarios dentro de los modelos de ML implementados.
Counterfit
Counterfit es una biblioteca desarrollada por Microsoft que permite a los investigadores realizar pruebas de ataque a los modelos de ML para detectar vulnerabilidades en los sistemas de IA antes de que lleguen a producción. Algo interesante de esta herramienta es que se puede utilizar para emular adversarios en frameworks como Caldera, ya que es útil para evaluar las técnicas en Adversarial ML Threat Matrix de MITRE y reproducirlas en los propios servicios de IA.
Conclusión
Tal como hemos visto en los diversos posts sobre los ataques a los modelos de ML, está claro que estos modelos presentan diversas vulnerabilidades. Lamentablemente, este tipo de tecnologías si bien manejan datos sensibles y se utilizan en diversos sectores de la industria, muchas veces no son desarrolladas teniendo en consideración la seguridad. De esta manera, así como MITRE ha desarrollado la matriz de amenazas ATLAS para ayudar a detectar los posibles ataques a estos modelos, es necesario que desde la industria se puedan implementar herramientas que evalúen la robustez de los modelos de ML antes de lanzarlos a producción.
Muchos consideran erróneamente que para realizar estos ataques hay que ser un experto; sin embargo, a principios de este año un usuario obtuvo múltiples cuentas verificadas de la aplicación ID.me mediante el envío de selfies en las que usaba simplemente una peluca. Esto le permitió utilizar estas cuentas para presentar falsos reclamos de desempleo y obtener alrededor de $900,000 dólares.
¿Cómo es que el sistema de ID.me posibilito esta estafa? Para comprobar la identidad de un contribuyente, esta aplicación que utiliza un modelo de IA simplemente solicita una foto de una licencia de conducir o pasaporte y luego tomar una selfie para comparar las imágenes. Claramente, si la robustez de este modelo hubiera sido evaluado previamente este incidente probablemente no hubiera ocurrido.



