

El machine learning es una tecnología que está generando un gran impacto en diferentes ámbitos y es cada vez más relevante. Podemos ver su uso en distintos escenarios, desde aplicaciones para la detección del rostro, sistemas de reconocimiento de voz, para la detección de malware y spam, aplicaciones del clima, en sectores como la salud, finanzas, y la lista podría seguir. Pero como vimos en el post “Introducción a los ataques dirigidos a modelos de machine learning (ML)”, esta tecnología presenta sus riesgos de seguridad. De hecho, hace dos años Microsoft aseguraba que “los ciberataques a sistemas de machine learning son más comunes de lo que se cree”. Entre 2019 y 2021 los sistemas de machine learning utilizados por compañías como Google, Amazon, Microsoft y Tesla han sufrido la manipulación de sus datos y lamentablemente muchas empresas no están preparadas y no saben cómo proteger sus sistemas de ML.
En este contexto, Gartner aseguró hace dos años que para el 2022 el 30% de todos los ciberataques a sistemas de IA aprovecharían el envenenamiento de datos de entrenamiento, el robo de modelos de IA o muestras adversas para atacar sistemas impulsados por IA. Y como ocurre con muchas otras tecnologías, crecen las implementaciones y el desarrollo de estos modelos pero lamentablemente no siempre incluyen la perspectiva de seguridad en el proceso. Por eso, consideré útil compartir algunas recomendaciones a la hora de implementar la seguridad en estos modelos apoyándonos en lo mencionado por NIST.

Seguridad en ML
Parte del gran desafío es que muchos de estos sistemas son cajas negras, ya que en su mayoría no es posible acceder a los modelos, es decir, a la lógica de procesamiento. Sin embargo, cierto está que los cibercriminales solo necesitan encontrar una grieta en las defensas de un sistema para desplegar un ataque adversario.
Según el paper publicado por NIST se utilizará diferentes métodos de defensa dependiendo de cuál sea la fase del proceso de Machine Learning:
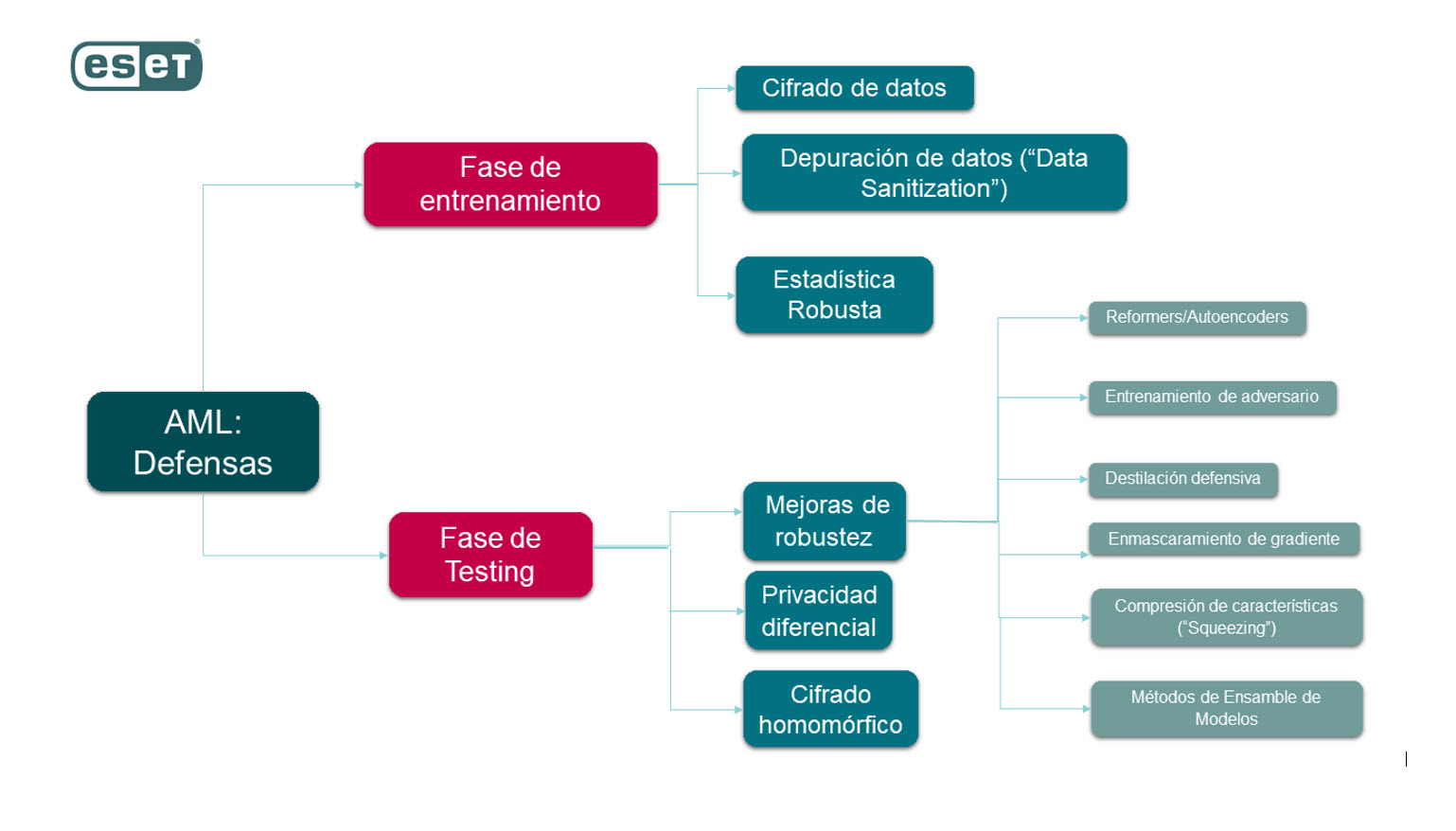
AML: Detalles de tipos de defensas NIST
Métodos de Defensa
Defensa en fase de Entrenamiento
Los ataques en la fase de entrenamiento están relacionados con el acceso a los datos. En este caso algunas de las herramientas que podemos tener en cuenta a la hora de resguardar los datos del modelo son:
Cifrado de datos
Es una de las principales herramientas para la protección de los datos. En este caso se utiliza para limitar el acceso solamente a sistemas o usuarios autorizados.
Depuración de datos a través de “Rechazo por impacto negativo”
Dentro de la depuración de datos (del inglés Data Sanization), los ejemplos “contradictorios” se identifican probando los impactos de los ejemplos en el desempeño de la clasificación; aquellos ejemplos contradictorios que causen tasas de error altas en la clasificación se eliminan del conjunto de entrenamiento, en un enfoque conocido como “Rechazo por impacto negativo” (Reject on Negative Impact).
Estadística robusta
En lugar de intentar detectar datos envenenados, las estadísticas robustas utilizan restricciones y técnicas de regularización para reducir las posibles distorsiones del modelo de aprendizaje causadas por datos envenenados.
Defensa en fase de Testing
Mejoras de robustez:
Entrenamiento de adversario
Las entradas que contienen perturbaciones adversas, pero con etiquetas de salida correctas, se inyectan en los datos de entrenamiento para minimizar los errores de clasificación causados por ejemplos adversarios.
Enmascaramiento de gradiente
Reduce la sensibilidad del modelo a pequeñas perturbaciones en las entradas calculando las derivadas de primer orden del modelo con respecto a sus entradas y minimizando estas derivadas durante la fase de aprendizaje.
Destilación defensiva
Es utilizada cuando se usa un modelo de destino para entrenar un modelo más pequeño que exhibe una superficie de salida más suave.
Métodos de Ensamble de Modelos
También conocidos como “métodos combinados”, son diseñados con el fin de aumentar el rendimiento de los modelos; en síntesis, estos modelos están formados por múltiples clasificadores que se entrenan juntos y se combinan para mejorar la solidez.
Compresión de características
Este método utiliza transformaciones de suavizado de características de entrada en un intento de deshacer las perturbaciones adversas.
Reformers/Autoencoders:
Los reformadores toman una entrada determinada y la empujan hacia el ejemplo más cercano en el conjunto de entrenamiento, generalmente usando redes neuronales llamadas Autoencoders, para contrarrestar las perturbaciones adversas.
Privacidad diferencial
Las mejoras de robustez se pueden dar a partir de la aplicación con el entrenamiento del modelo o de la salida de los modelos proveyendo “Garantías diferenciales de privacidad”, la cual es aquella propiedad asociada al mecanismo de aleatorización en pares de conjuntos de datos adyacentes. En última instancia, la propiedad de privacidad diferencial garantiza que los resultados del modelo no revelen ninguna información adicional sobre un registro individual, incluido en los datos de entrenamiento. Sin embargo, existe una compensación de rendimiento inherente porque la precisión de la predicción de un modelo se degrada por los mecanismos de aleatorización utilizados para lograr la privacidad diferencial.
Cifrado homomórfico
Cifra los datos de forma que, por ejemplo, una red neuronal puede procesar sin descifrar los datos. Esto protege la privacidad de cada entrada individual, pero introduce una sobrecarga de rendimiento computacional y limita el conjunto de operaciones aritméticas a las que admite el cifrado homomórfico.
Conclusión
Es verdad que hablar de defensas podría incurrir en gastos generales de rendimiento y tener hasta incluso un efecto perjudicial en la precisión del modelo, pero ya en la actualidad sabemos que estos modelos de ML controlan muchos procesos de la vida diaria. La pregunta es: ¿Por qué no implementar seguridad en nuestro modelos de ML? Como dijo Vicent Rijmen, uno de los padres de la criptografía: “La seguridad siempre implica un coste en rendimiento”.



