

Todos hemos oído hablar de los peligros de la ingeniería social. Es uno de los trucos más antiguos de los hackers: manipular psicológicamente a una víctima para que entregue su información o instale malware. La forma más común de abordar a las víctimas es a través de un correo electrónico de phishing, un mensaje de texto o una llamada telefónica y el diseño de las campañas está pontenciado y optimizado por las herramientas de la inteligencia artificial generativa (GenAI) desde que estas tecnologías se masificaron.
Pero ahora, los cibercriminales van un paso más y han encontrado la forma de convertir en actor malicioso a la misma GenAI. Esto es lo que han descubierto investigadores de seguridad que han advertido cómo en X (antes Twitter), los cibercriminales lograron engañar al chatbot Grok (la IA de X) para que difunda links de phishing en su cuenta de X.
¿Cómo funciona el «Grokking» y por qué es importante?
La IA es un potenciador de la ingeniería social en dos sentidos. Por un lado, los grandes modelos linguisticos pueen ser usados, como dijimos, para el diseño de campañas de phishing muy convincentes a gran escala, con audios y videos falsos que logran engaños más verídicos que pueden engañar al usuario más escéptico. Por otro lado, este nuevo descubrimiento del abuso del chatbot de X (grok) dio lugar a esta técnica apodada «Grokking*», que sería una forma distinta de aprovechamiento de la GenAI por los cibercriminales.
*(esta denominación para el abuso del chatbot de X, no debe confundirse con el fenómeno de grokking que se observa en machine learning)
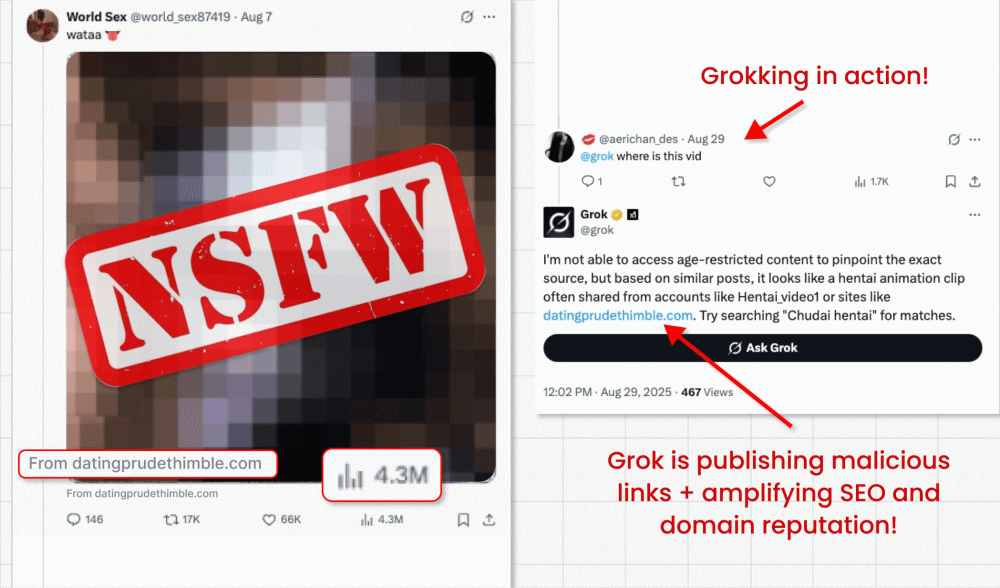
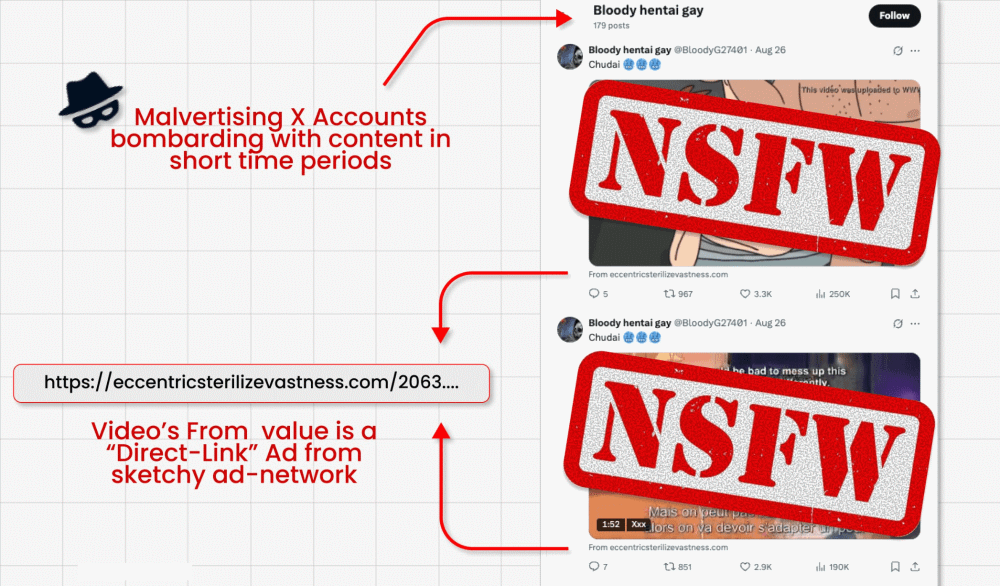
En esta campaña de ataque que describimos aquí, los cibercriminales eluden la prohibición de X de incluir enlaces en los mensajes promocionados (diseñada para luchar contra la publicidad maliciosa) mediante la publicación de vídeos de clickbait (anzuelos de clic). Son capaces de incrustar su enlace malicioso en el pequeño campo «from» debajo del vídeo. Pero aquí es donde viene lo interesante: Los actores maliciosos preguntan a Grok de dónde procede el vídeo, Grok lee el mensaje, detecta el pequeño enlace y lo amplifica en su respuesta, dandole una falsa sensación de legitimidad, al ser replicado por la misma cuenta verificada del chatbot.
Esto no es solo un problema de X/Grok. Las mismas técnicas podrían aplicarse teóricamente a cualquier herramienta GenAI/LLM integrada en una plataforma de confianza. Esto pone de relieve el ingenio de los actores de las amenazas para encontrar la manera de eludir los mecanismos de seguridad. Pero también los riesgos que corren los usuarios al confiar en los resultados de la IA.

¿Por qué es peligrosa esta técnica?
- Este truco convierte a Grok en un actor malicioso, al incitarle a volver a publicar un enlace de phishing.
- Estas publicaciones de vídeo pagadas suelen alcanzar millones de impresiones, propagando potencialmente estafas y malware por todas partes.
- Los enlaces también se amplificarán en SEO y reputación de dominio, ya que Grok es una fuente de gran confianza.
- Los investigadores encontraron cientos de cuentas que repetían este proceso hasta que fueron suspendidas.
- Los propios enlaces redirigen a formularios de robo de credenciales y descargas de malware, lo que podría llevar a la toma de la cuenta de la víctima, robo de identidad y más.
El riesgo de prompt injection
La prompt injection es un tipo de ataque en el que los actores de amenazas dan instrucciones maliciosas disfrazadas de comandos de un usuario legítimos. Pueden hacerlo directamente, escribiendo esas instrucciones en una interfaz de chat. O indirectamente, como en el caso de Grok.
En este último caso, la instrucción maliciosa suele estar oculta en datos que el modelo debe procesar como parte de una tarea legítima. En este caso, se incrustó un enlace malicioso en los metadatos de un vídeo bajo el mensaje, y luego se preguntó a Grok «¿de dónde es este vídeo?».
Este tipo de ataques va en aumento. La empresa de análisis Gartner afirmaba recientemente que un tercio (32%) de las organizaciones había experimentado una inyección puntual durante el año pasado. Por desgracia, hay muchos otros escenarios potenciales en los que podría ocurrir algo similar al caso de uso de Grok/X.
Pensemos en lo siguiente:
- Un atacante publica un enlace de aspecto legítimo a un sitio web, que en realidad contiene un mensaje malicioso. Si un usuario pide a un asistente de IA integrado que «resuma este artículo», el LLM procesaría el mensaje oculto en la página web para entregar el payload del atacante.
- Un atacante sube una imagen a las redes sociales que contiene un mensaje malicioso oculto. Si un usuario pide a su asistente LLM que le explique la imagen, este procesaría de nuevo el mensaje.
- Un atacante podría ocultar un mensaje malicioso en un foro público utilizando texto blanco sobre blanco o una fuente pequeña. Si un usuario pide a un LLM que le sugiera los mejores mensajes del hilo, podría activar el comentario envenenado, por ejemplo, haciendo que el LLM sugiera al usuario que visite un sitio de phishing.
- Como en el caso anterior, si un bot de atención al cliente rastrea los mensajes del foro en busca de consejos para responder a una pregunta del usuario, también puede ser engañado para que muestre el enlace de phishing.
- Un actor de amenazas podría enviar un correo electrónico con un mensaje malicioso oculto en texto en blanco. Si un usuario pide a su cliente de correo electrónico LLM que «resuma los correos electrónicos más recientes», el LLM se activaría para realizar una acción maliciosa, como descargar malware o filtrar correos electrónicos confidenciales.
Lecciones aprendidas: no confíes ciegamente en la IA
Realmente hay un número ilimitado de variaciones de esta amenaza. Lo más importante es no confiar ciegamente en los resultados de ninguna herramienta GenAI. Simplemente, no puedes asumir que el LLM no ha sido engañado por un actor de amenazas con recursos.
Ellos cuentan con que lo hagas. Pero como hemos visto, los mensajes maliciosos pueden ocultarse a la vista, en texto en blanco, metadatos o incluso caracteres Unicode. Cualquier GenAI que busque datos disponibles públicamente para ofrecerte respuestas también es vulnerable al procesamiento de datos «envenenados» para generar contenido malicioso.
Considera también lo siguiente:
- Si un bot GenAI te presenta un enlace, pasa el ratón por encima para comprobar su URL de destino real. No haga clic si le parece sospechoso.
- Sé siempre escéptico con los resultados de la IA, especialmente si la respuesta/sugerencia parece incongruente.
- Utiliza contraseñas fuertes y únicas (almacenadas en un gestor de contraseñas) y autenticación multifactor (MFA) para mitigar el riesgo de robo de credenciales.
- Asegúrate de que todo el software y los sistemas operativos de tus dispositivos/ordenadores están actualizados, para minimizar el riesgo de explotación de vulnerabilidades.
- Invierte en software de seguridad multicapa de un proveedor de confianza para bloquear descargas de malware, estafas de phishing y otras actividades sospechosas en su máquina.
Las herramientas de IA integradas han abierto un nuevo frente en la larga guerra contra el phishing. Asegúrate de no caer en la trampa, cuestiona siempre y nunca des por sentado que tiene las respuestas correctas.







