

Si bien un análisis estático de código fuente puede tener diversos fines, es cierto que muchas veces son necesarios para cumplir con estándares de seguridad y calidad de software. Asimismo, existen diversos estándares que contemplan aspectos de seguridad según las necesidades que se requieran cumplir y el software que se requiera auditar. Por el análisis estático de código en sí, podemos asumir que el mismo se define como el proceso de evaluar software sin ejecutarlo, entendiendo el concepto de evaluar como la ejecución de cualquier tipo de mecanismo que se pueda aplicar para que tomando el código fuente que haya escrito un desarrollador o Software Factory, podamos extraer información que tenga cierto valor, ya sea para el equipo de desarrollo, para un equipo de auditoria, una capa de gestión, o para sea quien sea el usuario final o fines de dicha evaluación.
A continuación, abordaremos aspectos del análisis estático de código fuente orientado a seguridad tanto en un marco teórico como práctico.
- El análisis estático de código fuente orientado a seguridad dentro de los estándares de seguridad de software
- Metodologías y herramientas para el análisis estático de código fuente orientado a seguridad
- Fases de construcción un analizador estático de código fuente
- Conclusiones
El análisis estático de código fuente orientado a seguridad dentro de los estándares de seguridad de software
Hoy día se exige cada vez más a las organizaciones cumplir con los estándares de seguridad. En el caso del desarrollo de software podemos observar los siguientes estándares que dentro de sus ciclos incorporan el análisis estático de código fuente orientado a seguridad.
- CLASP (Comprehensive, LightweightApplicationSecurityProcess): Modelo prescriptivo, basado en roles y buenas prácticas que permite a los equipos de Desarrollo implementar seguridad en cada una de las fases del Ciclo de Vida de Desarrollo en forma estructurada, medible y repetible.
- OpenSAMM (Software Assurance Maturity Model): Marco abierto para ayudar a las organizaciones a formular e implementar una estrategia de seguridad de software que se adapte a los riesgos específicos que enfrenta la organización.
- Touchpoints: Conjunto de mejores prácticas de seguridad de software que ponen en práctica la seguridad desde la fase inicial del desarrollo.
- Microsoft SDL (Security Development Lifecycle): El ciclo de vida de desarrollo de seguridad (SDL) es un proceso de control de seguridad orientado al desarrollo de software. Siendo una iniciativa corporativa y una directiva obligatoria desde el año 2004, SDL tiene como objetivo reducir el número y la gravedad de las vulnerabilidades en el software.
Metodologías y herramientas para el análisis estático de código fuente orientado a seguridad
Como mencionamos anteriormente, existen diversos estándares que dentro de las metodologías de desarrollo seguro contemplan análisis estático de código fuente. Ahora bien, en cuanto al análisis estático de código orientado a seguridad debemos destacar metodologías tales como OWASP conjuntamente con las de SDLC, las cuales proponen marcos y técnicas de ejecución para el análisis estático de código fuente orientado a seguridad sumado a sus respectivas guías de ejecución, revisión y SCP. Por otra parte, dentro de las herramientas de análisis de código en general existen diversas opciones según el tipo de análisis que se requiera ejecutar, tales como SAST, DAST, IAST y RASP; aunque para hablar específicamente de análisis estático de código orientado a seguridad solo nos servirían las herramientas de tipo SAST, para las cuales OWASP también cuenta con una lista de herramientas verificadas y con gran información dentro de la comunidad. A continuación, repasamos algunos aspectos de este tipo de herramientas:
Pros:
- Corrigen vulnerabilidades en su origen (concretamente en el SDLC, donde es más fácil solucionarlas) mediante líneas de código de asignación de firmas que se sabe que presentan riesgos.
- Sin impacto en el entorno de producción
- Fomenta una buena higiene del código al integrarse directamente en el entorno de desarrollo
- Valioso para prácticas de desarrollo seguras
Contras:
- Requiere diferentes implementaciones para diferentes lenguajes o marcos
- Difícil de administrar si no se está en el equipo de desarrollo
- Difícil de implementar a gran escala
- No sustituye a la creación de aplicaciones pensando en la seguridad
- No se ejecuta durante el tiempo de ejecución de la aplicación
Como podemos observar, están bástate repartido los pros y contras de este tipo de herramientas, aunque más allá de estos aspectos y yendo más a cómo funcionan internamente, podemos destacar que la mayoría de las mismas está compuesta con base en mecanismos y técnicas que remiten a la teoría de compiladores, pudiendo por medio de su implementación lograr extraer información del código que se esté analizando.
A continuación, repasamos las técnicas más relevantes:
Técnicas para extraer información de un código fuente

Imagen 1. Técnicas y mecanismos para el análisis estático de un código fuente
Grep análisis: Utilidad para el uso de regular expresión —palabras reservadas— detección de contraseñas visibles.
Identation Code: Utilidad para verificar que una vez que se abren llaves esté bien identado el código —esto puede evitar fallos de seguridad, como por ejemplo apple-go-tofail.
DataFlowAnalysis: Utilidad para, desde un punto de partida, encontrar la pertenencia con un punto final.
Propagación de constante: Utilidad para, teniendo una constante definida en un sitio, ver cómo se propagaría esa constante dentro del código fuente.
Alias análisis: Utilidad para hacer análisis de punteros.
A partir de estas técnicas y mecanismos de análisis estático de código podemos recabar mucha información que, en nuestro caso, será sin dudas información relativa a la seguridad del código que estemos auditando. Para esta tarea OWASP TOP 10 se vuelve un marco de referencia excelente, ya que contempla la evaluación de las vulnerabilidades más relevantes del software, tales como FileInclusion, XSS, SQLInjection, entre otras; pero más allá de esta guía y lejos de intentar ser mecánicos, es importante considerar que dentro del análisis estático de código existen diferentes tipos y categorías según las respuestas que tengamos para las siguientes preguntas:
- ¿Qué código se está auditando? (código fuente o binarios)
- ¿Qué propiedad es la que se está auditando? (seguridad - corrección - optimización - complejidad -finitud - tamaño)
Tipos de análisis de código fuente

Imagen 2. Tipos de análisis y técnicas utilizadas a la hora de realizar el análisis estático de código
Tal como vemos en el cuadro anterior, existen diversos tipos de análisis y técnicas utilizadas a la hora de realizar el análisis estático de código según el tipo de análisis que se quiera ejecutar. Otra de las cuestiones importantes que se deben considerar es la categoría de la información que vamos a recolectar. Así como al momento de realizar pruebas de penetración de una aplicación web, a groso modo podemos encontrar vulnerabilidades de tipo configuración, actualización, y programación, en el caso del análisis estático de código esta es una situación particular y a veces un poco ambigua, ya que dentro del análisis podemos encontrar defectos de violación, bugs, o vulnerabilidades que comparten algunas de estas características entre sí.
Bugs: Diferencia entre lo que el programador pretendía que el software hiciera y lo que hace realmente. Los bugs difícilmente pueden ser detectados automáticamente, pues la intención de un desarrollador siempre es subjetiva. Por ello, para este tipo de detecciones normalmente se realizan análisis de tipo UnitTest.
Violación: Diferencia entre cómo el programador codificó su software y cómo lo habría hecho un “programador ideal”. Sin dudas es especulativo el término de “programador ideal”, pero refiere al deber ser de la codificación de software según el marco teórico del lenguaje. Muchas violaciones pueden ser detectadas automáticamente si utilizamos las herramientas adecuadas.
Vulnerabilidad: Cuando hablamos de vulnerabilidades podemos concluir que son un hibrido entre bug y violación; es decir, es un subconjunto de violaciones relacionadas con fallos de seguridad. Un caso típico de esta situación es cuando un desarrollador hace uso, por ejemplo, de un SELECT para acceder a una base de datos. En un caso genérico esto provocaría una concatenación de variable, lo que implicaría a su vez una violación, ya que evidentemente esta no sería la mejor manera de hacerlo; pero también puede considerarse un bug, ya que el desarrollador no pretende que esta situación suceda. Por otra parte, la detección de una vulnerabilidad jamás asegura su explotación y persistencia, ya sea porque existen capas de seguridad que lo limitan o diversas situaciones que pueden generar el mismo resultado.
Si bien es cierto que disponemos de las herramientas de tipo SAST para el análisis estático de código, al final este tipo de herramientas están más orientadas a la calidad de código que a la seguridad. Por otra parte, su potencial normalmente se aprecia al incorporarse en la etapa 0 de desarrollo, situación que es poco habitual en la generalidad del software, ya que todavía la mayoría de organismos y desarrolladores programan sus aplicaciones sin contemplar a la seguridad desde el diseño. En general la mayor parte del código que se requiere auditar en los distintos entornos ya fue programado, y en el peor de los casos fue programado por un tercero que no se dispone a brindar información. Esto sin dudas tiene que ver con una cuestión vinculada tanto a aspectos culturales como económicos, pero lo cierto es que a la hora de realizar el trabajo de análisis las limitaciones de estas herramientas hacen que no podamos cumplir de manera acabada con nuestros objetivos. Esto no deja más alternativa —en el ideal caso— que tener que confeccionar nosotros mismos un analizador estático de código fuente que se adapte a nuestras necesidades. A continuación, repasamos cuáles son las fases de construcción de un analizador estático de código fuente junto a sus características y aspectos más relevantes.
Fases de construcción un analizador estático de código fuente
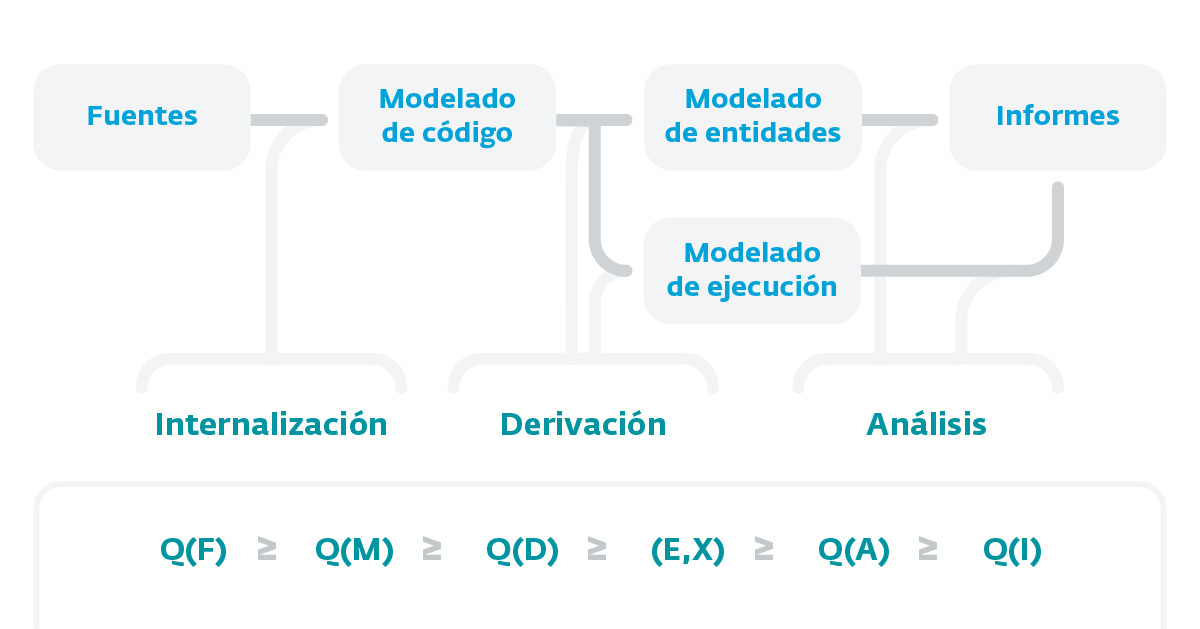
Imagen 3. Fases de construcción de un analizador estático de código fuente.
Tal como se aprecia en el esquema que se describe en la Imagen 1, las fases de construcción de un analizador estático de código fuente se compone de un proceso tipo pipeline formado por distintas etapas que se ejecutan una seguido de la otra. Esto hace que la información de salida de una etapa sea el punto de entrada de la que le sigue, por lo que es muy importante —sobre todo en la primera fase de internalización— la calidad de cada etapa al depender una de la otra. Como punto de partida de todo este proceso debemos considerar el código fuente que queremos analizar, pudiendo ser código fuente generado o código máquina, y asumir siempre que el código generado en el proceso de building no se puede considerar, ya que no estaríamos hablando de fuentes.
A partir de las fuentes, lo que se intenta realizar es un modelado del código con la intención de generar una visión abstracta del mismo y lo más fiel posible (Internalización), para luego generar un modelado del conjunto de entidades y un modelado de ejecución (derivación). Para ello se puedan aplicar técnicas de análisis que nos permitan extraer información del código (análisis) y luego arribar al proceso de generación de informes.
Tal como mencionábamos anteriormente, la primera fase (Internalización) es la más importante, ya que la calidad de las restantes etapas depende de esta. Por otra parte, es la etapa más compleja y laboriosa dentro de todo el proceso de construcción.
A continuación, analizamos sus características y las etapas de construcción:
Etapa de Internalización (opciones y problemáticas)
Nuestro objetivo en la etapa de internalización es intentar aplicar técnicas como las de parseo para generar un AST o estructura similar para transformar las fuentes proporcionadas en una estructura que el analizador “entienda”.
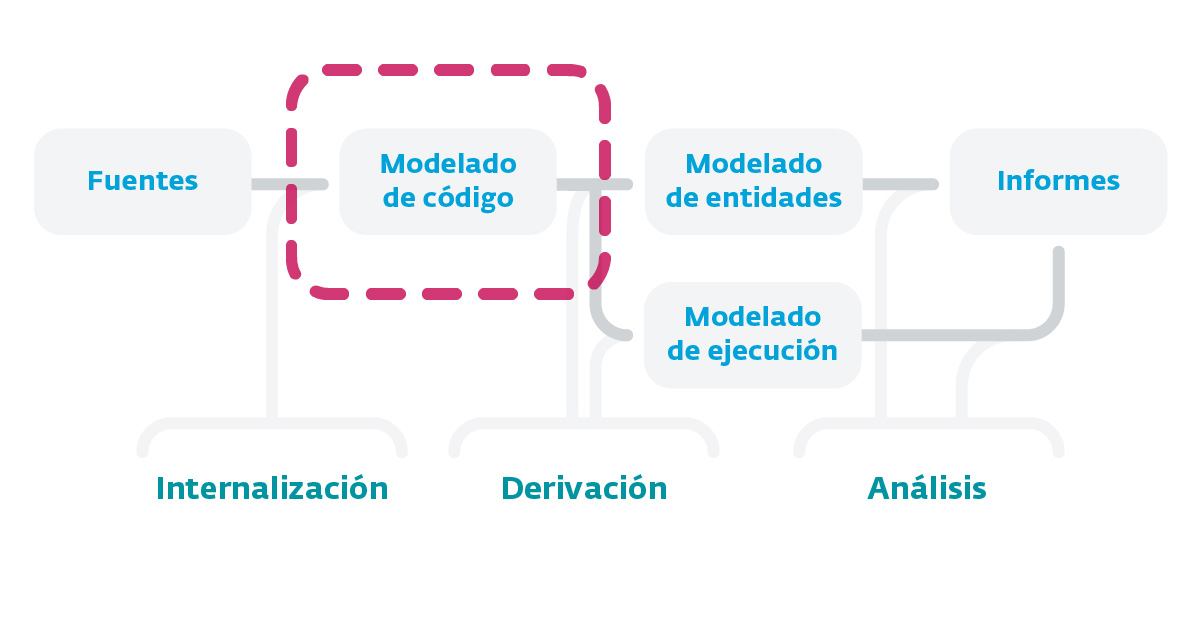
Imagen 4.
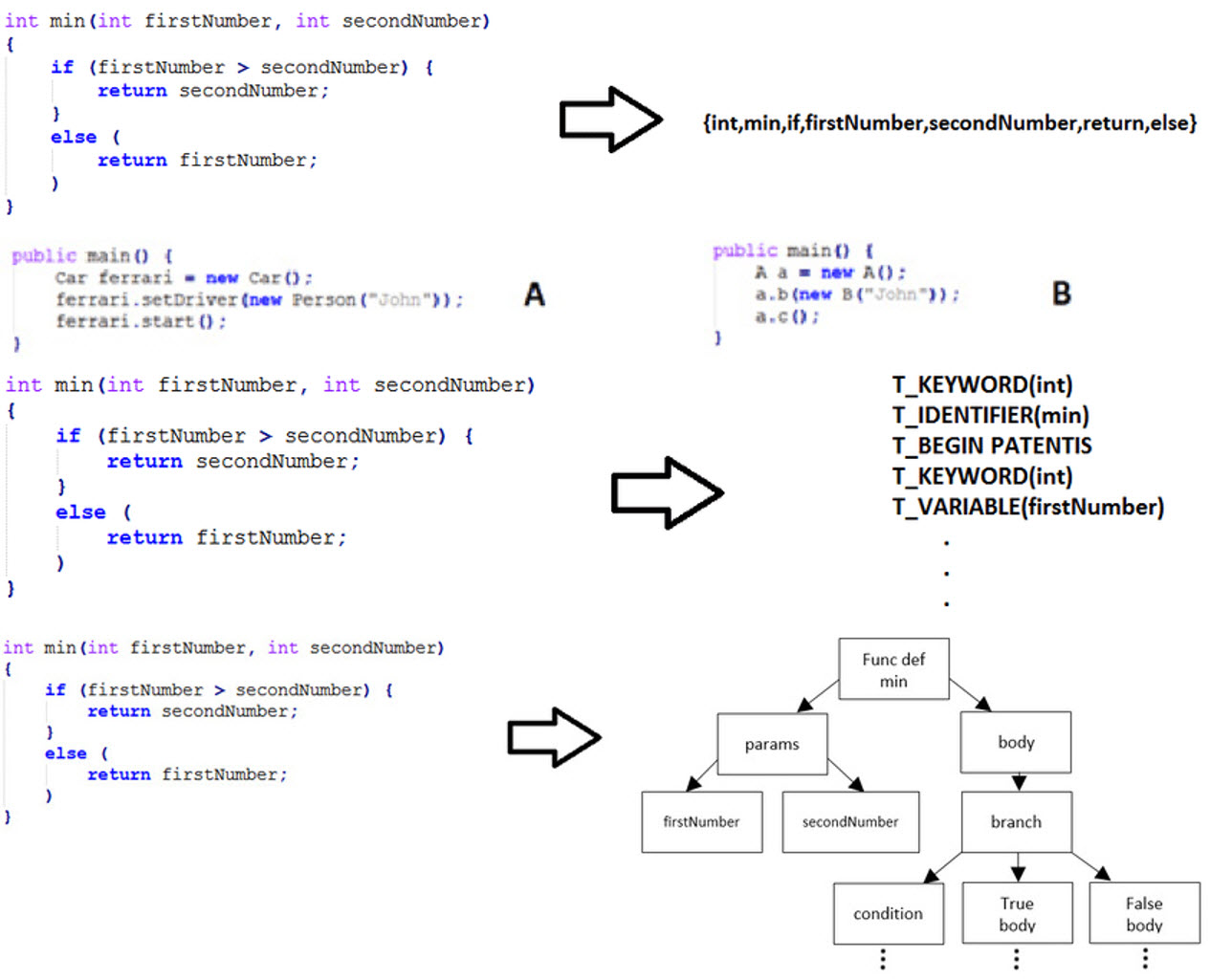
Imagen 5. Autores: Michal Ďuračík, Emil Krsak, Patrik Hrkút. Fuente: Researchgate.
Para esta tarea de “transformación”, los Compiler Frontends suelen ser la solución univoca, pues generalmente son sencillos de implementar y fáciles de ejecutar. A continuación destacamos los siguientes:
- Gcc: Orientado a C
- Mono: orientado a lenguajes .NET
- Eclipse: utilizándolo mediante un mecanismo de plugins (JDT) son buenas alternativas, ya que están depuradas y muchas veces son rápidas, como en el caso de Eclipse + JDT, logrando arrojar rápidamente una estructura de la aplicación.
Es cierto también que, aunque estas herramientas parezcan la gloria, muchas veces hacen que no sea tan sencillo este proceso de internalización. Si por ejemplo decidimos utilizar Eclipse con sus distintos plugins, tenemos que consideraren que en muchos casos el trabajo se nos convertirá engorroso, ya que en concreto son herramientas pensadas para un IDE, por lo que muchas veces nos genera trabajo extra teniendo que crear proyecto y configuraciones extras; todas tareas que nos desvían de nuestro propósito. Por otra parte, en cuanto a las estructuras que se generan, las mismas están pensadas para que un usuario interactúe con ellas, lo que nos genera muchas veces tener que descartarlas como opción posible. En cuanto a la representación que generan suelen ser algo más visual que una estructura posiblemente manipulable.
Por otra parte, al no ser estas herramientas específicas para el análisis de código generan interferencia, ya que cuando intentamos generar los modelos con estas herramientas lo hacen desde la última etapa de compilación, por lo que al final no se tiene una vista del código original ya que estas hacen una transformación del código fuente a un código derivado (ej. C + macros). Todo compilador tiene un preanálisis que convierte macros en código (recuperando el código y transformándolo para obtener un código con todo resulto para proceder con la compilación, pero cuando se reporta un error, no se reporta del código original sino del código más la resolución de las macros). En compilación esto no es problemático, pero sí a la hora de indicar donde están los errores. En cuanto a cómo resolver estos problemas, no queda más que realizar las tareas de manera manual. Para esto revisaremos algunas opciones disponibles.
Opciones para realizar el proceso de internalización manualmente (LALR/GLR/Parsers/Generators/PEG/Parser Combiators)
Tal como mencionamos anteriormente, si las herramientas disponibles no solucionan el trabajo de internalización, contamos con las técnicas clásicas de teoría de compiladores para llevar a cabo un proceso alternativo. Se pueden utilizar técnicas de parseo, técnicas de gramática, generadores automáticos de parsin, entre otros; pero también es cierto que no todo es color de rosa, ya que no todos los lenguajes son iguales. Quizás para un lenguaje como JAVA puede existir mucha información, pero quizás para C o C# nos puede generar un gran reto que nos obliga afrontar diversas problemáticas, entre las que se destacan las siguientes:
- Problemáticas de la Internalización
- Reconocer Sintaxis
- Resolver ambigüedades sintácticas
- Resolver ambigüedades dependientes de la semántica y el contexto
- Resolver referencias
Reconocer Sintaxis
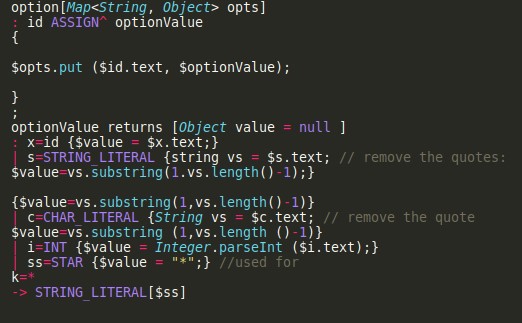
Imagen 6
Entre las herramientas para llevar a cabo un proceso de reconocimiento de sintaxis contamos, por ejemplo, con los generadores de parseadores/analizadores: ANTLR, BISON, FLEX. Estos proveen un mecanismo que al escribir el código nos permite generar una máquina de estado que expresa la gramática que se ha establecido. Lo problemático es que es muchas veces es código complejo de entender y mantener; sobre todo si hay mucha gente involucrada.
Ambigüedades Sintácticas
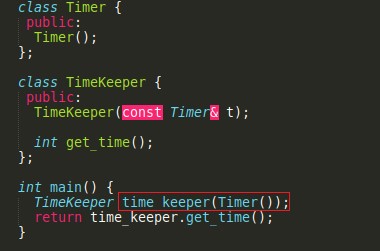
Imagen 7
Una vez que ya contamos con la gramática y estamos parseando el código fuente empieza la fase de resolución para la cual existen ambigüedades sintácticas durante el proceso de parseo que tenemos que resolver. Por ejemplo, en el caso del código C++ que se muestra en la Imagen 7, nos podemos plantear la siguiente pregunta: ¿está definiendo una variable llamada TimeKeeper utilizando timer como método de inicialización o está definiendo un método que se llama TimeKeeper que tiene un valor de retorno y tiene un parámetro sin nombre que es una función que devuelve timer? Esto es relativo y hay que definirlo, muchas veces la gramática va por un lado y lo que el usuario esperaba va por otro, lo que provoca mucha dificultad para resolver este tipo de situaciones.
Ambigüedades dependientes de la semántica y el contexto
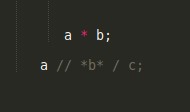
Imagen 8
En cuanto a la semántica nos podemos encontrar con una situación muy típica, tal como se muestra en la imagen VI. ¿La misma que significa a * b; es una multiplicación? Es una variable llamada b de tipo puntero a a, sin dudas esto dependerá de la semántica. Pero esto es importante, ya que según cómo entendamos esto se generará el AST. Si observamos el caso de a //*b*/c; es aún más complejo, pues según la versión del compilador puede querer decir diversas cosas generando ambigüedades difíciles de resolver.
Problemas de referencias
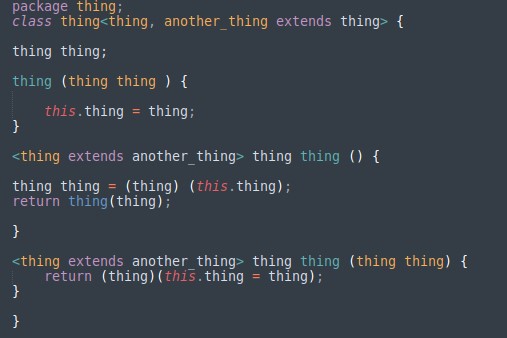
Imagen 9
En el caso de las referencias, tal como podemos observar en el ejemplo que se ve en la Imagen VII que contiene código JAVA, tendríamos que saber qué significa thing en cada caso. Si observamos el coloreado que muestra el IDE, el mismo no es correcto y a la vez contradictorio, ya que no es posible distinguir con claridad entre variables y tipos, lo que convierte a la resolución este tipo de situaciones en una labor que consume tiempo.
Reflexiones sobre la etapa de internalización
Tal como hemos observado a lo largo del proceso de internalización, no existen soluciones mágicas para realizar esta tarea. Siempre habrá que buscar la mejor solución a mano considerando que se necesitarán de grandes conocimientos del lenguaje a tratar (gramática, semántica, reglas de resolución, modelo de memoria del lenguaje), y que muchas veces la información no es pública o no existe (ASP), sumado también a saber muy bien qué es lo que se está haciendo y cuál es el objetivo, ya que es fácil perderse.
Etapa de Análisis del código (opciones y problemáticas)
Una vez generado los modelos internos en la etapa de internalización, nos toca la fase de análisis. A continuación, repasamos su estructura y algunos casos de análisis.
¿En que consiste concretamente la etapa de análisis?
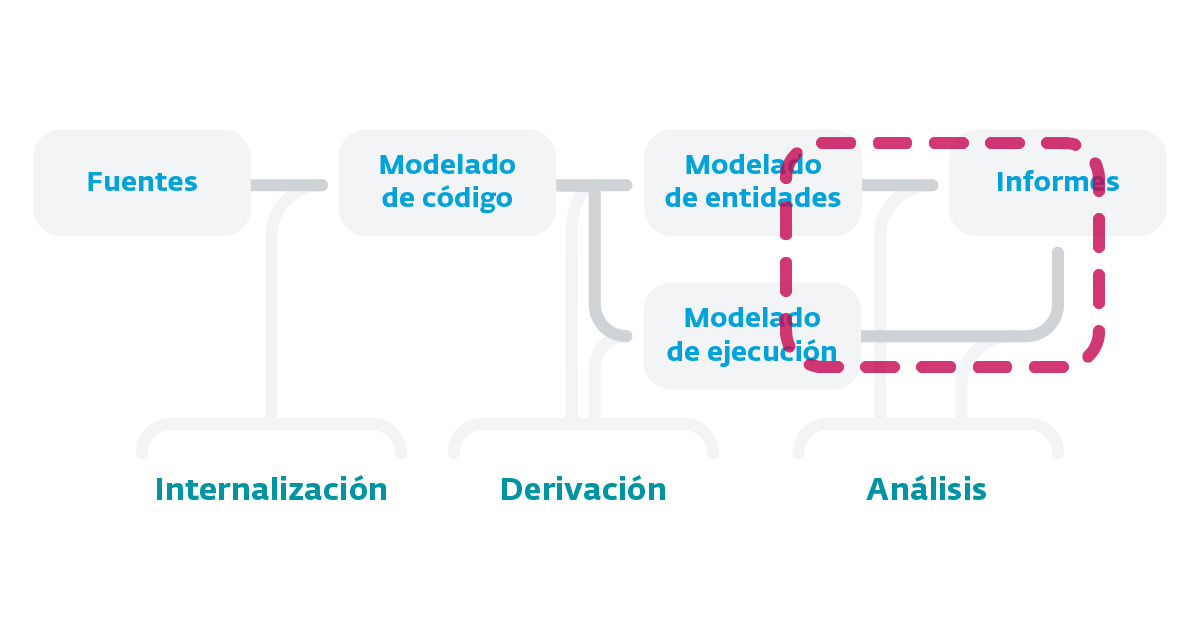
Imagen 10
La idea del análisis en sí será la de localizar todas las vulnerabilidades posibles, proceso para el cual están disponibles las siguientes técnicas:
Algunas técnicas existentes:
- Grep Análisis -Análisis de flujo de datos -Análisis basados en tipos -Análisis de regiones
- Interpretación abstracta
Algunos casos de análisis de código
- Caso de uso utilizando técnicas básicas de análisis estático de código

Imagen 11. Fuente: UNEEDSEC.
En el siguiente ejemplo podemos observar un caso donde se muestra un fichero de configuración del sistema filezilla. Si observamos la Imagen 11 se aprecia que contiene una contraseña en texto claro, información que si bien utilizando herramientas básicas como grep o cat podemos conseguir, las mismas presentan algunas de las siguientes adversidades que destacamos a continuación.
- Ratio de falsos positivos/negativos
- Líneas de código por hora
- Conocimiento de lenguajes/tecnologías
- Análisis de flujo: Caso “sencillo” (Backward & taint analysis)
Los análisis de flujo permiten incorporar técnicas y conocimientos precisos de análisis. A continuación analizamos sus características y aspectos más relevantes:
- Estudia la propagación de la información a lo largo del código fuente. Permite evaluar todos los posibles flujos de ejecución que llegan a un punto vulnerable (sink) desde una entrada de datos no seguro (source).
- Exige un conocimiento del modelo de memoria del lenguaje.
- Exige conocimiento de los mecanismos implícitos de propagación de la información del lenguaje.
- Exige modelado (o inclusión) de third party libraries.
- Caso básico de propagación de información
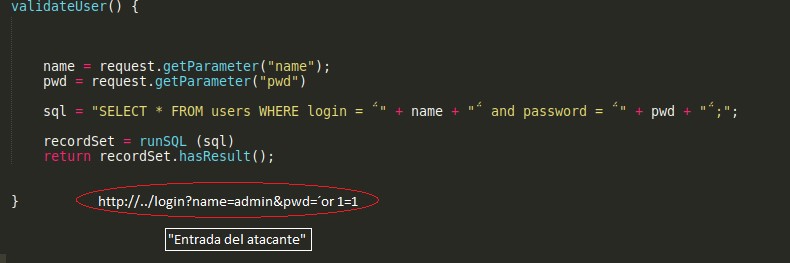
Imagen 12.a
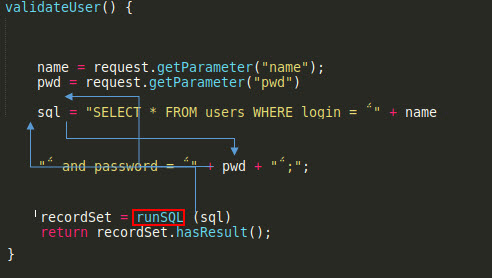
Imagen 12.b
Vemos como, un usuario malicioso manipulando los parámetros de entrada puede acceder a la aplicación. En la Imagen 13 se observa cómo se propaga la información entre el sync (el punto vulnerable) que es donde se ejecuta la consulta SQL y la entrada de datos procedente del usuario (source).
- Caso básico de propagación de información (Backward & taint analysis)
Código Fuente - Modelo de Memoria - Modelo de ejecución Modelo de Memoria
Imagen 13
En este caso (un poco más complejo) se observa cómo el método foo, que tiene el sink (el cual es el punto vulnerable), depende de la variable s, la cual no está dentro del código de la función, sino que depende de otro método que se está ejecutando desde s, donde se está asignando un valor. Esto sería el uso de una variable estática en programación general. Lo interesante de este tipo de análisis es que se puede observar con mucho detalle la propagación de información, ya que disponemos tanto de un modelo de ejecución como de un modelo de memoria que permiten apreciar la propagación de información sobre todo el código de manera ordena, dinámica y legible.
También debemos mencionar que entre las dificultades de este tipo de técnicas de análisis se destaca la complejidad para el análisis del uso de interlenguajes y también la complejidad en la evaluación de expresiones.
Reflexiones sobre las técnicas de análisis
Si bien es cierto que la tarea de análisis cuenta con sus problemáticas —tales como las del interlenguaje (ASPX/(C#), Android (Java/Dalvik) y la interpretación de sus flujos que hacen por ejemplo que sea compleja la evaluación de expresiones—, es un hecho que este tipo de trabajos nos aportan mucha calidad a nuestro análisis logrando generar menos fallos, más velocidad de proceso y una forma estandarizada de trabajar de acuerdo a nuestras necesidades. Esto nos permite ser capaces de dar valor a la semántica del lenguaje, cosa que no logra un auditor estándar. También podemos destacar el nivel de detalle de información versátil y moldeable a diversos fines o áreas de interés dependiendo de quién sea el usuario final.
Conclusiones
Creo que podemos afirmar que el análisis estático de código fuente no es tarea fácil. Hemos analizados las herramientas disponibles y también el proceso de creación de un analizador estático de código advirtiendo en ambas situaciones que existe una gran cantidad de adversidades que hay que estar dispuestos a atravesar para adentrarse en la tarea.
En cuanto a las conclusiones de cara a las herramientas disponibles, verdaderamente las herramientas OpenSource (pmd, sonar, findbug) podemos decir que están más orientadas a calidad de software que a seguridad, lo cual genera ciertas limitaciones, sobre todo para proyectos muy grandes. Esto muchas veces lleva a que las organizaciones se vean obligadas a invertir mucho dinero en aplicaciones desarrolladas por empresas dedicadas exclusivamente al análisis de seguridad de código (HP-Forty,Coverity, Veracode).
Mas allá de las herramientas disponibles y los procesos para generar analizadores de código, debemos señalar también que la tecnología crece muy rápido generando nuevos lenguajes y sistemas cada vez más complejos y grandes —más componentes, más lenguajes, uso de microservicios y lenguajes interpretados etc. A esto debemos sumar también que muchas veces el software no deja de crecer y que cada vez existen más capas de abstracción o que la cantidad de programadores no es suficiente, lo que amenaza la calidad de código. Además, que para las empresas prima la velocidad de desarrollo debido a la oportunidad de mercado.
En cuanto a los aspectos más técnicos, las técnicas de análisis que estuvimos repasando se encuentran migrando tecnológicamente, tal como lo están haciendo las empresas dedicas a proveer productos de análisis de código orientado a seguridad que se están mudando a tecnologías de big data y machine learning. Esto les permite abarcar muchas de las problemáticas antes mencionadas, produciendo, por ejemplo, gramáticas pseudo automáticas (identificación por machine learning asistido por humanos), reglas de resolución de referencias identificadas, entre otras.
Esto realmente cambia el paradigma del proceso de internalización, dado que los modelos de ejecución y análisis se generaran directamente de las reglas de inferencia sobre el código fuente. Algunos compiladores ya ofrecen API para trabajar sobre sus modelos internos, e incipientemente nace software para la tarea, como Deep-Code, Infer, sapienz, entre otros, que nos brindan la posibilidad de trabajar con machine learning, aunque todavía de modo muy limitado o más bien con muchos grises en el camino.
Sea utilizando las técnicas clásicas o las basadas en machine learning, y más allá del análisis estático en sí, en materia de calidad de análisis debemos destacar que siempre será necesario Identificar las posibilidades dinámicas del software a partir del código fuente (ficheros de configuración, librerías). El análisis estático se orienta más a sacar información de métodos, por ejemplo, pero también es muy importante y complementario obtener la componente dinámica, siendo capaces de proveer la mayor calidad de información y utilizar el código fuente para extraer información funcional de la aplicación.
Sin dudas, comprendiendo la complejidad del software actual y desde el punto de vista de la seguridad, un análisis de código estático nos resulta limitado en sus alcances para medir el estado de seguridad de un código. Esto sugiere que para lograr una vista general debamos contemplar soluciones como los análisis dinámicos, análisis de infraestructuras y el uso de capas de seguridad basadas en aplicaciones como Application Security Testing.
Fomentar permanente las buenas prácticas de programación dentro del ciclo de vida de desarrollo es un aspecto fundamental, pero no tiene sentido invertir en soluciones o análisis de cualquier tipo si no hay bases sólidas de desarrollo.
Otro de los aspectos importantes para la seguridad de nuestro código es medir constantemente el ciclo de desarrollo mediante auditorías internas y periódicas, generación de información estadística, generación de cuadro de mandos, entre otras aptitudes que podríamos destacar.



