Le ver Morris, en 1988 a été l'une de ces expériences bouleversantes qui ont révélé la rapidité avec laquelle un ver pouvait se propager à l'aide d'une vulnérabilité connue sous le nom de dépassement de mémoire tampon (ou buffer overflow). Environ 6 000 des 60 000 ordinateurs connectés à ARPANET, un précurseur d'Internet, ont été infectés par le ver Morris. Bien que cette attaque ait eu quelques effets positifs, notamment en poussant les fournisseurs de logiciels à prendre les vulnérabilités au sérieux et en créant la première équipe d'intervention en cas d'urgence informatique (CERT), cette attaque est loin d'être la dernière à tirer parti d'un dépassement de tampon.
En 2001, c’était au tour du ver Code Red d’infester plus de 359 000 ordinateurs utilisant le logiciel IIS de Microsoft. Code Red a défiguré des pages Web et tenté de lancer des attaques par déni de service, notamment sur un serveur Web de la Maison Blanche.
Puis, en 2003, le ver SQL Slammer a quant à lui attaqué plus de 250 000 systèmes utilisant le logiciel SQL Server de Microsoft. SQL Slammer a fait planter des routeurs, ralentissant considérablement, voire arrêtant, le trafic réseau sur Internet. Les vers Code Red et SQL Slammer se sont propagés par le biais de vulnérabilités de dépassement de tampon.
Plus de trente ans après le ver Morris, nous sommes toujours en proie aux vulnérabilités de dépassement de tampon avec toutes leurs conséquences négatives. Bien que certains accusent divers langages de programmation, ou certaines de leurs caractéristiques, d'avoir une conception peu sûre, le coupable semble être davantage l'utilisation faillible de ces langages. Pour comprendre comment les débordements de mémoire tampon se produisent, nous devons en savoir un peu plus sur la mémoire, en particulier la pile, et sur la façon dont les développeurs de logiciels doivent gérer la mémoire avec soin lorsqu'ils écrivent du code.
Qu'est-ce qu'un tampon et comment un dépassement de tampon peut se produire?
Une mémoire tampon est un bloc de mémoire attribué à un logiciel par le système d'exploitation. Il incombe au programme de demander au système d'exploitation la quantité de mémoire dont il a besoin pour fonctionner correctement. Dans certains langages de programmation comme Java, C#, Python, Go et Rust, la gestion de la mémoire se fait automatiquement. Dans d'autres langages comme C et C++, les programmeurs ont la charge de gérer manuellement l'allocation et la libération de la mémoire et de s'assurer que les limites de la mémoire ne sont pas dépassées en vérifiant la longueur des tampons.
Cependant, que ce soit par les programmeurs qui utilisent les bibliothèques de code de manière incorrecte ou par ceux qui les écrivent, des erreurs peuvent être commises. Celles-ci sont à l'origine de nombreuses vulnérabilités logicielles prêtes à être découvertes et exploitées. Un programme correctement conçu doit spécifier la taille maximale de la mémoire pour contenir les données et garantir que cette taille n'est pas dépassée. Un dépassement de tampon se produit lorsqu'un programme écrit des données au-delà de la mémoire qui lui est attribuée et dans un bloc de mémoire contigu destiné à un autre usage ou appartenant à un autre processus.
Étant donné qu'il existe deux principaux types de débordements de mémoire tampon - basés sur le tas et sur la pile - un mot préliminaire s'impose concernant la différence entre le tas et la pile.
La pile et le tas
Avant l'exécution d'un programme, le chargeur lui attribue un espace d'adressage virtuel qui comprend les adresses du tas et de la pile. Le tas est un bloc de mémoire qui est utilisé pour les variables globales et les variables auxquelles on attribue de la mémoire au moment de l'exécution (allouées dynamiquement).
Tout comme une pile d'assiettes à un buffet, une pile logicielle est construite à partir de cadres qui contiennent les variables locales d'une fonction appelée. Les cadres sont poussés (mis sur) la pile lorsque les fonctions sont appelées et retirés (enlevés) de la pile lorsqu'elles reviennent. S'il y a plusieurs threads, il y a plusieurs piles.
Une pile est très rapide par rapport à un tas, mais son utilisation présente deux inconvénients. Premièrement, la mémoire de la pile est limitée, ce qui signifie que placer de grandes structures de données sur la pile épuise plus rapidement les adresses disponibles. Deuxièmement, chaque trame a une durée de vie limitée à son existence sur la pile, ce qui signifie qu'il n'est pas valide d'accéder aux données d'une trame qui a été sortie de la pile. Si plusieurs fonctions doivent accéder aux mêmes données, il est préférable de placer les données sur la pile et de transmettre un pointeur vers ces données (leur adresse) à ces fonctions.
Les débordements de tampon peuvent se produire à la fois dans le tas et dans la pile, mais nous nous concentrerons ici sur la variété la plus courante : les débordements de tampon basés sur la pile.
Débordements de tampon basés sur la pile : Écraser l'adresse de retour
Comme les cadres sont empilés les uns sur les autres à chaque appel de fonction, les adresses de retour sont également poussées sur la pile, indiquant au programme où poursuivre l'exécution lorsqu'une fonction appelée se termine :
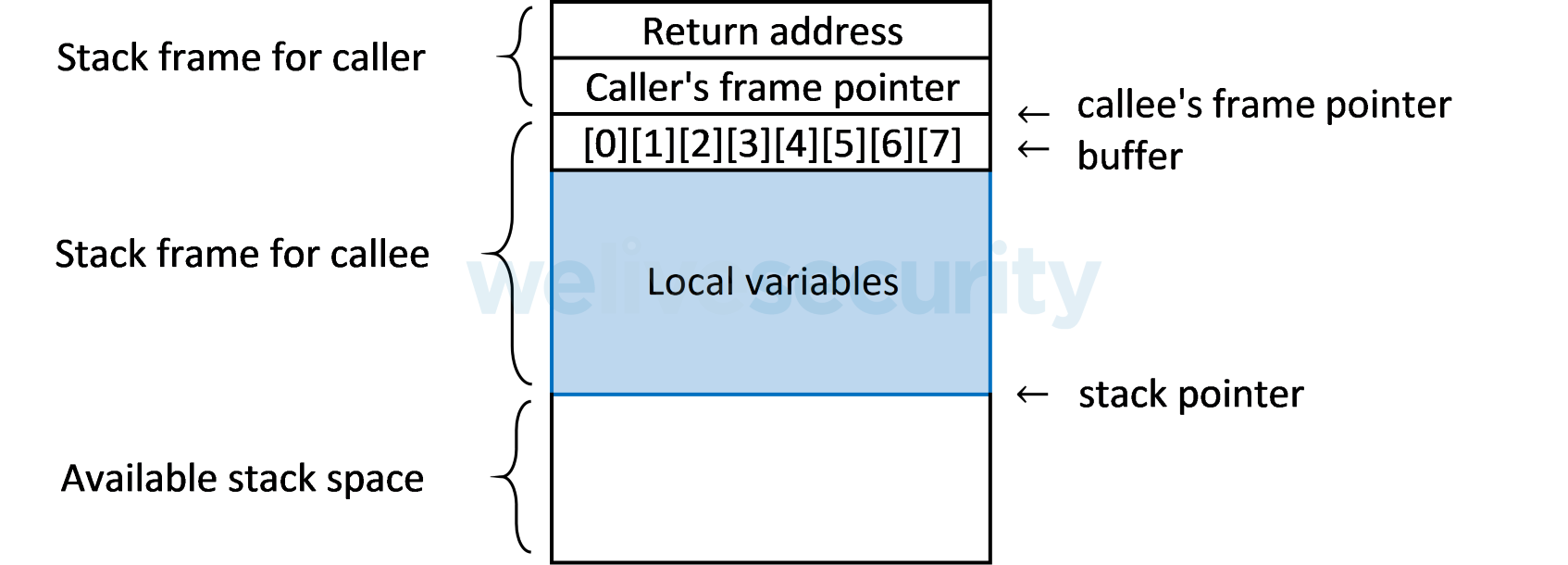
L'adresse de retour est située près des tampons qui contiennent les variables locales. Par conséquent, si un programme malveillant réussit à écrire plus de données dans un tampon qu'il ne peut en contenir, un dépassement de tampon se produit. Les données qui ne rentrent pas dans le tampon prévu peuvent déborder dans l'adresse de retour et l'écraser.
Si un dépassement de tampon se produit dans l'utilisation typique d'un programme vulnérable, le plus souvent, la nouvelle valeur de l'adresse de retour écrasée n'est pas un emplacement mémoire valide, ce qui signifie que le programme génère une erreur de segmentation de la mémoire et nécessite une reprise sur erreur - si cela n'est pas possible, le programme peut devenir instable ou même se planter lorsqu'il tente de revenir de la fonction dont le cadre de pile a été modifié par le dépassement. Toutefois, les cybercriminels peuvent tirer parti des débordements de tampon pour remplacer l'adresse de retour par un emplacement mémoire valide qui pointe directement vers leur code malveillant, ce qui leur permet dans de nombreux cas de lancer des shells et de prendre le contrôle total des ordinateurs des victimes. Le ver Stuxnet, par exemple, a utilisé une vulnérabilité de dépassement de tampon pour lancer un shell root.
Certains codes d'exploitation adoptent même une approche astucieuse consistant à réparer les dommages causés à la pile après l'exécution d'une action malveillante, afin de rétablir l'adresse de retour initiale. De cette façon, les attaquants tentent de dissimuler le détournement de l'instruction de retour, laissant le programme s'exécuter comme prévu par la suite.
Exemple - Codage de caractères hexadécimaux en valeurs d'octets
Pour les développeurs de logiciels intéressés par un débordement de tampon récent découvert en 2021, nous proposons le code suivant en C, qui est une version simplifiée et réécrite d'une vulnérabilité dans le routeur LTE ZTE MF971R suivie comme CVE‑2021‑21748 :
#include <stdio.h>
#include <string.h>
void encodeHexAsByteValues(const char *hexString, char *byteValues) {
signed int offset = 0;
int hexValues = 0;
int byte = 0;
while (offset < strlen(hexString)) {
strncpy((char *) &hexValues, &hexString[2 * offset], 2u);
sscanf((const char *) &hexValues, "%02X", &byte);
byteValues[offset++] = byte; // The return address can be overwritten opening a path for the
// insertion of exploit code
}
}
int main(void) {
const char* hexString = "0123456789ABCDEF01234";
char byteValues[4];
encodeHexAsByteValues(hexString, byteValues); // There is no size check to ensure that
// hexString is not too long for byteValues
// before calling the function
return 0;
}Pour en savoir plus, consultez mon Google Collaboratif.
Le programme ci-dessus démontre une fonction qui encode une chaîne composée de caractères compatibles avec l'hexadécimal sous une forme nécessitant la moitié de la mémoire. Deux caractères peuvent se substituer à des valeurs d'octet réelles (en hexadécimal), de sorte que les caractères « 0 » et « 1 », représentés par les valeurs d'octet 30 et 31, respectivement, peuvent être représentés littéralement par la valeur d'octet 01. Cette fonctionnalité a été utilisée dans le cadre de la gestion des mots de passe par le routeur ZTE.
Comme indiqué dans les commentaires du code, le hexString, d'une taille de 21 caractères, est trop grand pour le tampon byteValues , qui n'a qu'une taille de 4 caractères (même s'il peut accepter jusqu'à 8 caractères sous forme codée), et il n'y a pas de vérification pour s'assurer que la fonction encodeHexAsByteValues ne conduira pas à un dépassement de tampon.
Protection contre les attaques par débordement de tampon
Outre une programmation et des tests minutieux de la part des développeurs de logiciels, les compilateurs et les systèmes d'exploitation modernes ont mis en place plusieurs mécanismes visant à rendre les attaques par débordement de tampon plus difficiles à réaliser. Prenant l'exemple du pilote de compilateur GCC pour Linux, nous mentionnerons brièvement deux mécanismes qu'il utilise pour entraver l'exploitation des débordements de tampon : la randomisation de la pile et la détection de la corruption de la pile.
Randomisation de la pile
Le succès des attaques par dépassement de tampon repose en partie sur la connaissance d'un emplacement mémoire valide qui pointe vers le code d'exploitation. Par le passé, les emplacements de la pile étaient relativement uniformes, car les mêmes combinaisons de programmes et de versions de systèmes d'exploitation avaient les mêmes adresses de pile. Cela signifie que les attaquants pouvaient orchestrer une attaque - un peu comme une souche d'un virus biologique - pour attaquer la même combinaison programme-système d'exploitation.
La randomisation de la pile alloue une quantité aléatoire d'espace sur la pile au début de l'exécution d'un programme. Cet espace n'est pas destiné à être utilisé par le programme mais à permettre au programme d'avoir des adresses de pile différentes à chaque exécution.
Cependant, un attaquant persistant peut surmonter la randomisation de la pile en essayant de manière répétée d'obtenir des adresses différentes. Une technique consiste à utiliser une longue séquence d'instructions NOP (no operation), qui ne font qu'augmenter le compteur du programme, au début du code d'exploitation. L'attaquant n'a alors qu'à deviner l'adresse de l'une des nombreuses instructions NOP , au lieu de devoir deviner l'adresse exacte du début du code d'exploitation. C'est ce qu'on appelle une « NOP sled », car une fois que le programme saute à l'une de ces instructions NOP , il glisse entre les autres NOP jusqu'au début réel du code d'exploitation. Le ver Morris, par exemple, a commencé avec 400 instructions NOP .
Il existe toute une catégorie de techniques appelées "randomisation de la disposition de l'espace d'adressage" pour s'assurer que d'autres parties d'un programme, comme le code du programme, le code de la bibliothèque, les variables globales et les données du tas, ont des adresses mémoire différentes à chaque exécution du programme.
Détection de la corruption de la pile
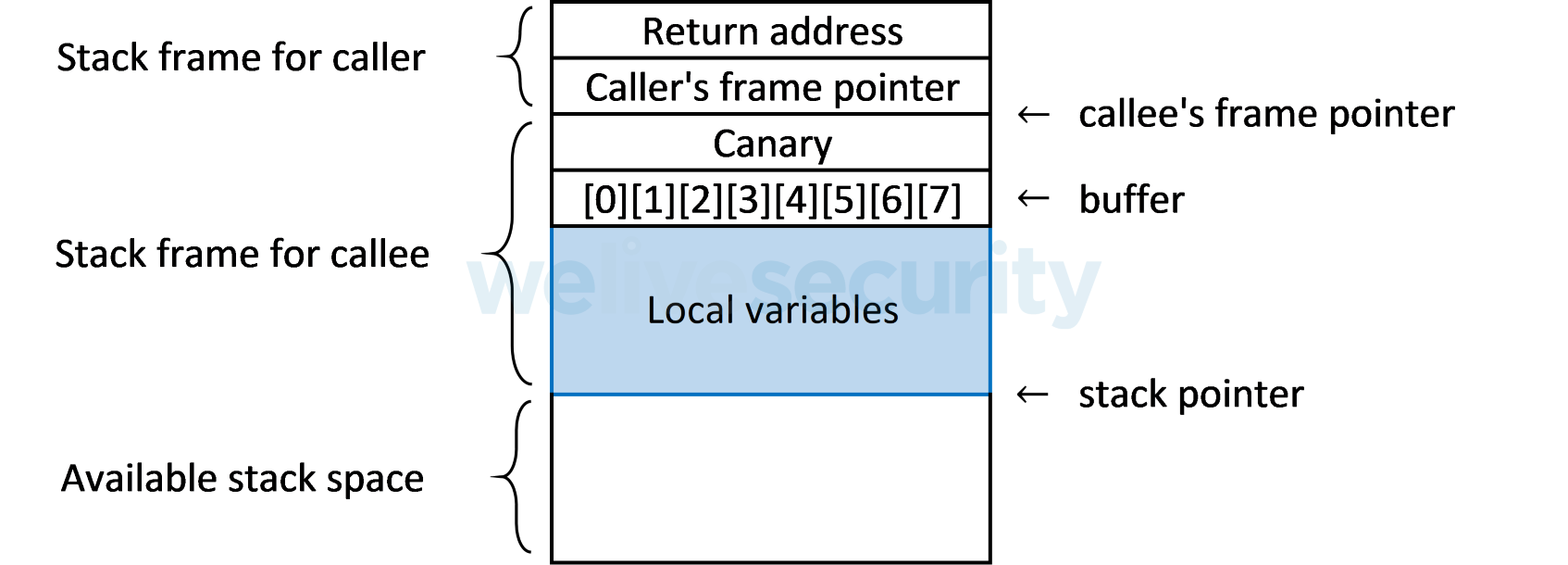
Une autre méthode pour prévenir une attaque par débordement de tampon consiste à détecter si la pile est corrompue. Un mécanisme courant est connu sous le nom de protecteur de pile, qui insère une valeur canari aléatoire, également appelée valeur de garde, entre les tampons locaux d'un cadre de pile et le reste de la pile. Avant de revenir d'une fonction, le programme peut alors vérifier l'état de la valeur canari et appeler une routine d'erreur si un débordement de tampon a modifié la valeur canari.
Un conseil final
Les vulnérabilités de débordement de tampon continuant d'être découvertes et corrigées, le meilleur conseil est de mettre en place une politique solide de mise à jour de toutes les applications et bibliothèques de code avec la plus haute priorité. En associant votre politique de mise à jour au déploiement de solutions de sécurité capables de détecter le code d'exploitation, vous pouvez considérablement augmenter les chances de succès des attaquants qui tentent d'exploiter les dépassements de tampon.
Lectures complémentaires :
Journée des programmeurs : des ressources pour vérifier votre code
Journée anti logiciels malveillants : l’évolution du code malveillant