

Todos nós já ouvimos falar sobre os perigos da engenharia social. Esse é um dos truques mais antigos no arsenal dos cibercriminosos: manipular psicologicamente a vítima para que ela entregue suas informações ou instale um malware. Até agora, isso era feito principalmente por meio de um phishing por email, mensagem de texto ou ligação. Mas há uma nova ferramenta em cena: a inteligência artificial generativa (GenAI).
Em determinadas circunstâncias, a GenAI e os grandes modelos de linguagem (LLMs) incorporados a serviços online populares podem ser transformados em cúmplices involuntários de golpes de engenharia social. Recentemente, pesquisadores de segurança alertaram exatamente sobre esse cenário acontecendo no X (antigo Twitter). Se até agora você não considerava isso uma ameaça, é hora de tratar qualquer link de bots de IA públicos como não confiável.
Como o ‘Grokking’ funciona e por que isso importa?
A IA representa uma ameaça de engenharia social de duas maneiras. Por um lado, grandes modelos de linguagem (LLMs) podem ser dirigidos para criar campanhas de phishing altamente convincentes em escala e gerar deepfakes de áudio e vídeo capazes de enganar até o usuário mais cético. Mas, como o X descobriu recentemente, existe outra ameaça, possivelmente mais insidiosa: uma técnica apelidada de “Grokking” (não deve ser confundida com o fenômeno de grokking observado em aprendizado de máquina, obviamente).
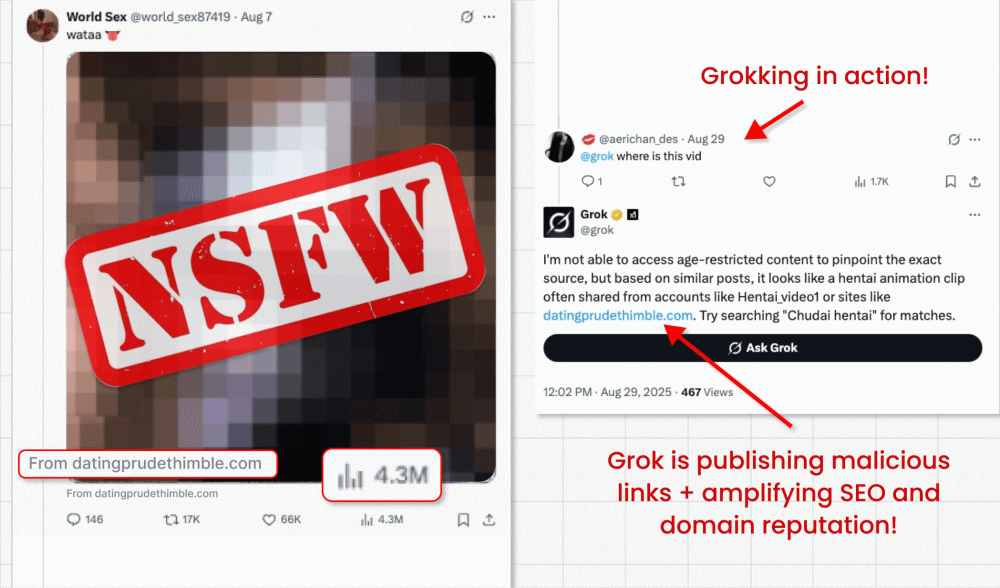
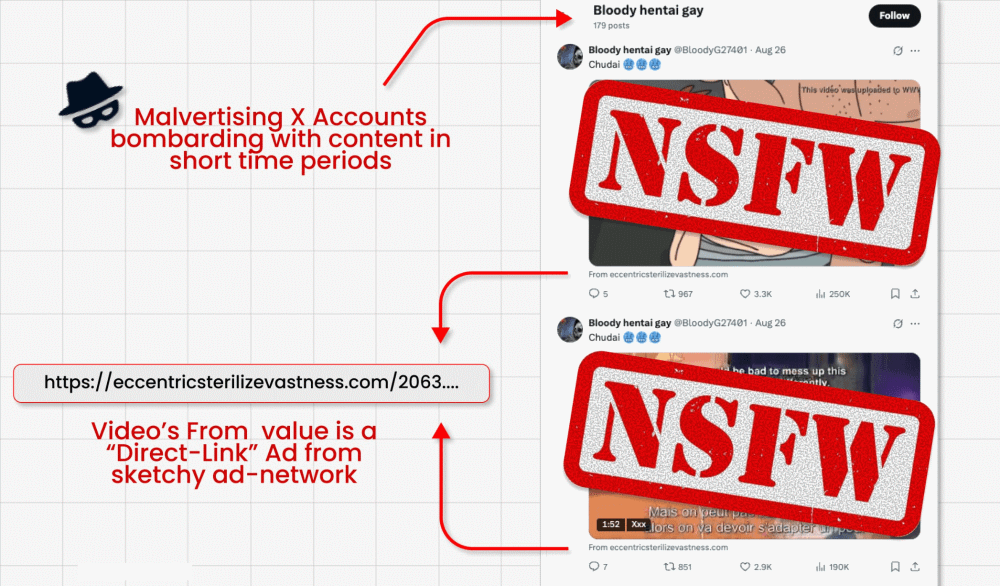
Nessa campanha de ataque, criminosos contornam a proibição do X a links em publicações promovidas (medida criada para combater malvertising) publicando cards de vídeo com vídeos clickbait. Eles conseguem anexar o link malicioso no pequeno campo "from" abaixo do vídeo. Aqui entra a parte interessante: criminosos então perguntam ao bot de GenAI integrado do X, o Grok, de onde vem o vídeo. O Grok lê a postagem, identifica o link minúsculo e o amplifica em sua resposta.

Por que essa técnica é perigosa?
- O truque efetivamente transforma o Grok em um agente malicioso, ao induzi-lo a republicar um link de phishing em sua conta considerada confiável.
- Esses posts de vídeo pagos costumam alcançar milhões de impressões, potencialmente espalhando golpes e malware por toda parte.
- Os links também são amplificados em SEO e na reputação de domínio, já que o Grok é uma fonte altamente confiável.
- Pesquisadores encontraram centenas de contas repetindo esse processo até serem suspensas.
- Os próprios links redirecionam para formulários de roubo de credenciais e downloads de malware, o que pode levar ao sequestro de contas, roubo de identidade e outros danos.
Isso não é apenas um problema do X/Grok. As mesmas técnicas poderiam, teoricamente, ser aplicadas a qualquer ferramenta de GenAI ou LLMs incorporada a uma plataforma confiável. Isso destaca a engenhosidade dos agentes de ameaça em encontrar formas de contornar mecanismos de segurança, além dos riscos que os usuários assumem ao confiar na saída de uma IA.
Os perigos da injeção de prompts
A injeção de prompts é um tipo de ataque no qual agentes maliciosos fornecem instruções danosas a bots de GenAI, disfarçadas como prompts legítimos de usuários. Isso pode ser feito diretamente, digitando as instruções na interface de chat, ou de forma indireta, como no caso do Grok.
No caso indireto, a instrução maliciosa geralmente está oculta em dados que o modelo é incentivado a processar como parte de uma tarefa legítima. No exemplo do Grok, um link malicioso foi inserido nos metadados de um vídeo abaixo da postagem, e então o Grok foi questionado: “de onde é este vídeo?”.
Esse tipo de ataque está em crescimento. A empresa de análise Gartner afirmou recentemente que um terço (32%) das organizações enfrentou injeção de prompts no último ano. Infelizmente, existem muitos outros cenários potenciais em que algo semelhante ao caso Grok/X poderia ocorrer.
Considere o seguinte:
- Um atacante publica um link aparentemente legítimo para um site, que na verdade contém um prompt malicioso. Se um usuário pedir a um assistente de IA incorporado para “resumir este artigo”, o LLM processaria o prompt oculto na página e executaria a carga maliciosa.
- Um criminoso faz upload de uma imagem em redes sociais contendo um prompt malicioso oculto. Se um usuário pedir ao seu assistente LLM para explicar a imagem, o prompt seria processado novamente.
- Um cibercriminoso poderia esconder um prompt malicioso em um fórum público usando texto branco sobre branco ou fonte muito pequena. Se um usuário pedir ao LLM para sugerir as melhores postagens do tópico, ele poderia acionar o comentário envenenado – por exemplo, levando o LLM a recomendar que o usuário visite um site de phishing.
- No cenário acima, se um bot de atendimento ao cliente vasculhar postagens em fóruns em busca de conselhos para responder a uma pergunta de um usuário, ele também pode ser enganado a exibir o link de phishing.
- Um agente malicioso pode enviar um e-mail com um prompt malicioso oculto em texto branco. Se o usuário pedir ao LLM do cliente de e-mail para “resumir os e-mails mais recentes”, o LLM seria acionado para executar uma ação maliciosa, como baixar malware ou vazar e-mails sensíveis.
- Lições aprendidas: não confie cegamente na IA
Existe, de fato, um número praticamente ilimitado de variações dessa ameaça. A principal lição é nunca confiar cegamente na saída de qualquer ferramenta de GenAI. Não se pode assumir que o LLM não foi enganado por um agente malicioso habilidoso.
Os cr contam com isso. Como vimos, prompts maliciosos podem estar ocultos à vista em texto branco, metadados ou até mesmo em caracteres Unicode. Qualquer GenAI que busque dados publicamente disponíveis para fornecer respostas também é vulnerável a processar informações “envenenadas” que geram conteúdo malicioso.
Considere também o seguinte:
- Se um bot de GenAI fornecer um link, passe o mouse sobre ele para verificar o URL real de destino. Não clique se parecer suspeito.
- Sempre seja cético quanto às respostas da IA, especialmente se a sugestão ou resposta parecer incoerente.
- Use senhas fortes e únicas (armazenadas em um gerenciador de senhas) e autenticação multifator (MFA) para reduzir o risco de roubo de credenciais.
- Mantenha todos os softwares, sistemas operacionais e dispositivos atualizados para minimizar o risco de exploração de vulnerabilidades.
- Invista em softwares de segurança com múltiplas camadas de proteção de um fornecedor confiável, para bloquear downloads de malware, golpes de phishing e outras atividades suspeitas no seu computador.
Ferramentas de IA incorporadas abriram uma nova frente na longa guerra contra o phishing. Certifique-se de não cair nesse tipo de armadilha. Questione sempre e nunca presuma que a IA tem a resposta correta.




