
Dans le nouveau module de cryptominage que nous avons découvert et décrit dans notre article précédent, les cybercriminels à l'origine du botnet Stantinko ont introduit plusieurs techniques d'obscurcissement, dont certaines n'ont pas encore été décrites publiquement. Dans le présent article, nous disséquons ces techniques et décrivons les contre-mesures possibles contre certaines d'entre elles.
Pour contrecarrer l'analyse et éviter la détection, le nouveau module de Stantinko utilise diverses techniques d'obfuscation :
- Obfuscation des chaînes - les chaînes significatives sont construites et ne sont présentes en mémoire que lorsqu'elles doivent être utilisées
- Obfuscation du flux de contrôle - la transformation du flux de contrôle en une forme difficile à lire et l'ordre d'exécution des blocs de base est imprévisible sans une analyse approfondie
- Code mort - ajout d'un code qui n'est jamais exécuté ; il contient également des exportations qui ne sont jamais appelées. Son but est de rendre les fichiers plus légitimes pour éviter la détection
- Code « ne rien faire » - c’est-à-dire l’ajout de code qui est exécuté, mais qui n'a pas d'effet matériel sur la fonctionnalité globale. Il est destiné à contourner les détections comportementales
- Chaînes et ressources mortes - ajout de ressources et de chaînes sans incidence sur la fonctionnalité
Parmi ces techniques, les plus notables sont l'obfuscation des chaines et du flux de contrôle. Nous les décrirons en détail dans les sections suivantes.
Obfuscation des chaînes
Toutes les chaînes de caractères intégrées dans le module sont sans rapport avec la fonctionnalité réelle. Leur source est inconnue et elles servent soit d'éléments de base pour la construction des chaînes qui sont réellement utilisées, soit elles ne sont pas utilisées du tout.
Les chaînes réellement utilisées par le logiciel malveillant sont générées en mémoire afin d'éviter la détection basée sur des fichiers et l'analyse de contrecarrer. Elles sont formées en réorganisant les octets des chaînes de leurre - celles qui sont intégrées dans le module - et en utilisant des fonctions standard pour la manipulation des chaînes, telles que strcpy(), strcat(), strncat(), strncpy(), sprintf(), memmove()et leurs versions Unicode.
Comme toutes les chaînes à utiliser dans une fonction particulière sont toujours assemblées séquentiellement au début de la fonction, on peut émuler les points d'entrée des fonctions et extraire les séquences de caractères imprimables qui surgissent pour révéler les chaînes.
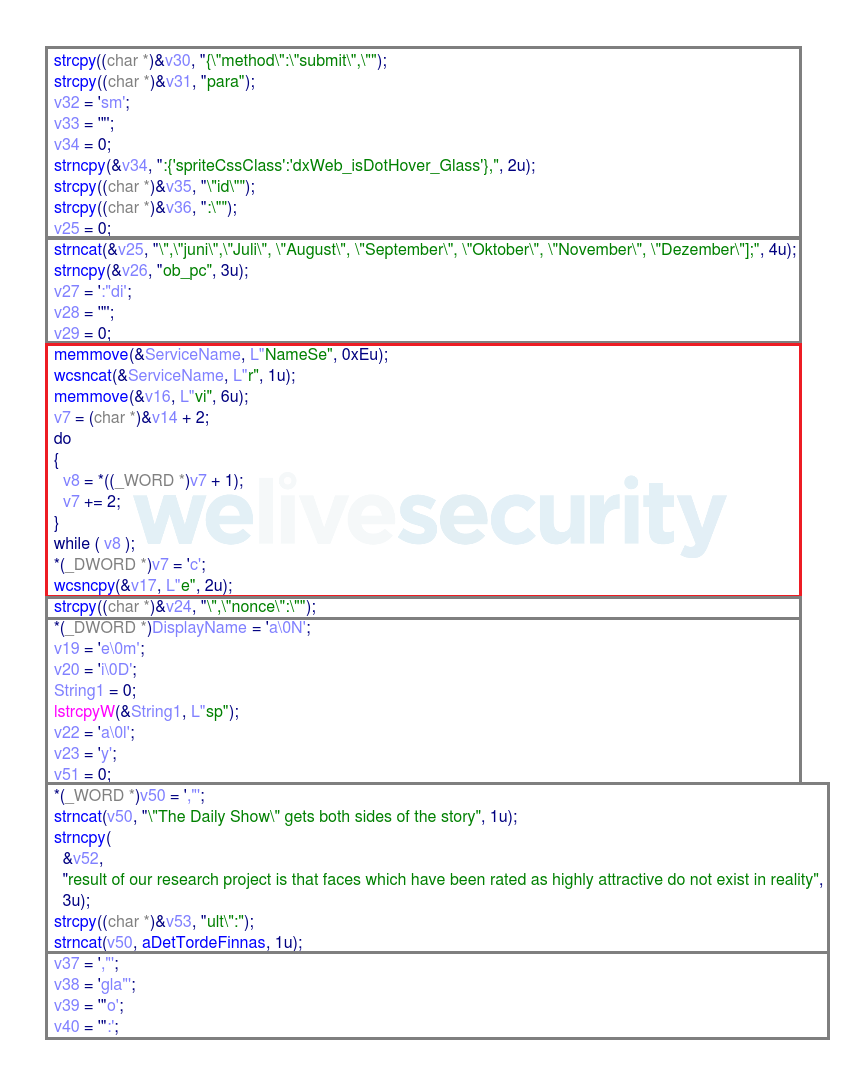 Figure 1. Exemple d'obfuscation de chaînes de caractères. Il y a 7 chaînes de leurres surlignées dans l'image. Par exemple, celle qui est marquée en rouge génère la chaîne « NameService ».
Figure 1. Exemple d'obfuscation de chaînes de caractères. Il y a 7 chaînes de leurres surlignées dans l'image. Par exemple, celle qui est marquée en rouge génère la chaîne « NameService ».
Aplanissement du flux de contrôle
L'aplanissement du flux de contrôle est une technique d'obfuscation utilisée pour contrecarrer l'analyse et éviter la détection.
L'aplanissement commun des flux de contrôle est obtenu en divisant une fonction unique en blocs de base. Ces blocs sont ensuite placés sous forme de dépêches dans une instruction de commutation à l'intérieur d'une boucle (c'est-à-dire que chaque dépêche est constituée d'un seul bloc de base). Une variable de contrôle permet de déterminer quel bloc de base doit être exécuté dans l'instruction de commutation ; sa valeur initiale est attribuée avant la boucle.
Un ID est attribué à tous les blocs de base et la variable de contrôle contient toujours l'ID du bloc de base à exécuter.
Tous les blocs de base fixent la valeur de la variable de contrôle à l'ID de son successeur (un bloc de base peut avoir plusieurs successeurs possibles ; dans ce cas, le successeur immédiat peut être choisi dans une condition).
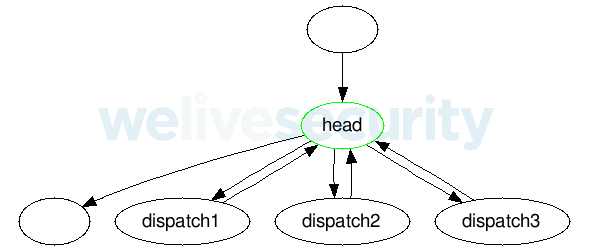
Figure 2. Structure de la boucle commune de contrôle-aplanissement-débit
Il existe différentes approches pour résoudre cette obscurantisme, comme l'utilisation de l'API de microcode de l'IDA. Rolf Rolles a utilisé cette méthode pour identifier ces boucles de manière heuristique, extraire la variable de contrôle de chaque bloc aplati et les réarranger en fonction des variables de contrôle.
Cette approche – tout comme d'autres similaires - ne fonctionnerait pas sur l'obfuscation de Stantinko, car elle présente certaines caractéristiques uniques par rapport aux obfuscations courantes d'aplanissement des flux de contrôle :
- Le code est aplani au niveau du code source, ce qui signifie également que le compilateur peut introduire certaines anomalies dans le binaire résultant
- La variable de contrôle est incrémentée dans un bloc de contrôle (à expliquer plus tard), et non dans des blocs de base
- Les dépêches contiennent plusieurs blocs de base (la division peut être disjonctive, c'est-à-dire que chaque bloc de base appartient à une seule dépêche, mais parfois les dépêches s'entremêlent, ce qui signifie qu'elles partagent certains blocs de base)
- Les boucles d'aplanissement peuvent être imbriquées et successives
- Les fonctions multiples sont fusionnées.
Ces caractéristiques montrent que Stantinko a introduit de nouveaux obstacles à cette technique qui doivent être surmontés afin d'analyser sa charge utile finale.
Aplanissement du flux de contrôle de Stantinko
Dans la plupart des fonctions de Stantinko, le code est divisé en plusieurs dépêches (décrites ci-dessus) et deux blocs de contrôle - une tête et une queue - qui contrôlent le flux de la fonction.
La tête décide quelle répartition doit être exécutée en vérifiant la variable de contrôle. La queue augmente la variable de contrôle d'une constante fixe et retourne à la tête ou sort de la boucle d'aplanissement :
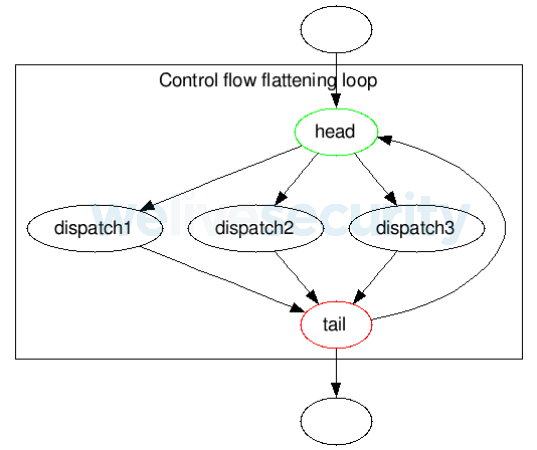
Figure 3. Structure régulière de la boucle d'aplanissement du flux de contrôle de Stantinko
Stantinko semble aplatir le code de toutes les fonctions et corps de construction de haut niveau (comme une boucle), mais parfois il a aussi tendance à choisir des blocs de code apparemment aléatoires. Comme il applique les boucles d'aplanissement des flux de contrôle à la fois sur les fonctions et les constructions de haut niveau, elles peuvent être naturellement imbriquées et il arrive aussi qu'il y ait plusieurs boucles consécutives.
Lorsqu'une boucle d'aplanissement du flux de contrôle est créée en fusionnant le code de plusieurs fonctions, la variable de contrôle de la fonction fusionnée résultante est initialisée avec des valeurs différentes, en fonction de la fonction d'origine appelée. La valeur de la variable de contrôle est transmise à la fonction résultante en tant que paramètre.
Nous avons surmonté cette technique d'obscurcissement en réorganisant les blocs dans le binaire ; notre approche est décrite dans la section suivante.
Il est important de noter que nous avons observé de multiples anomalies dans certaines des boucles d'aplanissement qui rendent plus difficile l'automatisation du processus de désobfuscation. La majorité d'entre elles semblent être générées par le compilateur ; cela nous amène à penser que l'obfuscation d'aplanissement des flux de contrôle est appliquée avant la compilation.
Nous avons constaté les anomalies suivantes; elles peuvent apparaître séparément ou en combinaison :
- Certaines dépêches peuvent n'être que du code mort - elles ne seront jamais exécutées. (Exemples dans la section « Code mort à l'intérieur de la boucle d'aplanissement du flux de contrôle » ci-dessous).
- Les blocs de base à l'intérieur des dépêches peuvent s'entremêler, ce qui signifie qu'ils peuvent contenir un code commun.
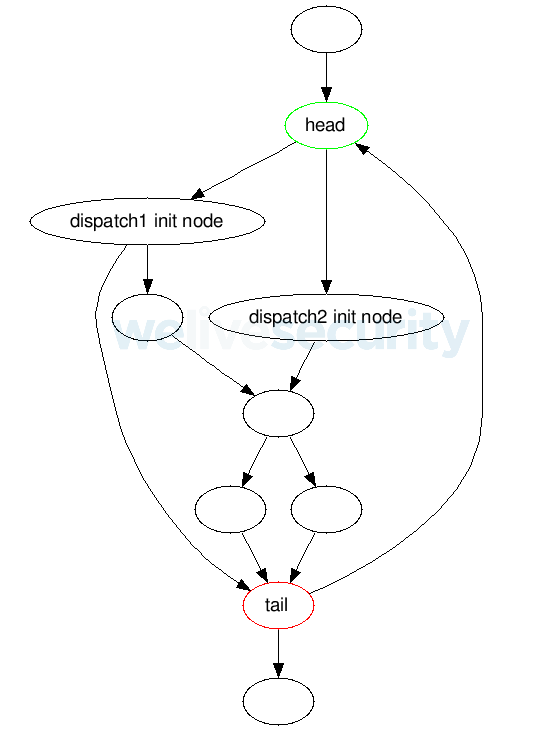
Figure 4. Structure d'une boucle d'aplanissement avec des dépêches partageant un code commun
- Il y a des sauts directs des dépêches vers un bloc à l'extérieur de la boucle d'aplanissement, juste derrière la queue, et vers les blocs qui reviennent de la fonction.
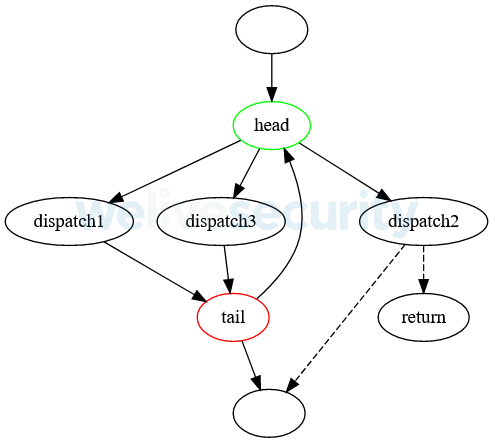
Figure 5. Structure d'une boucle d'aplanissement dont la dépêche sort directement de la boucle. Une seule des lignes en pointillés se produit.
- Il peut y avoir plusieurs queues, ou aucune queue du tout - dans ce dernier cas, la variable de contrôle est augmentée à la fin de chaque envoi.
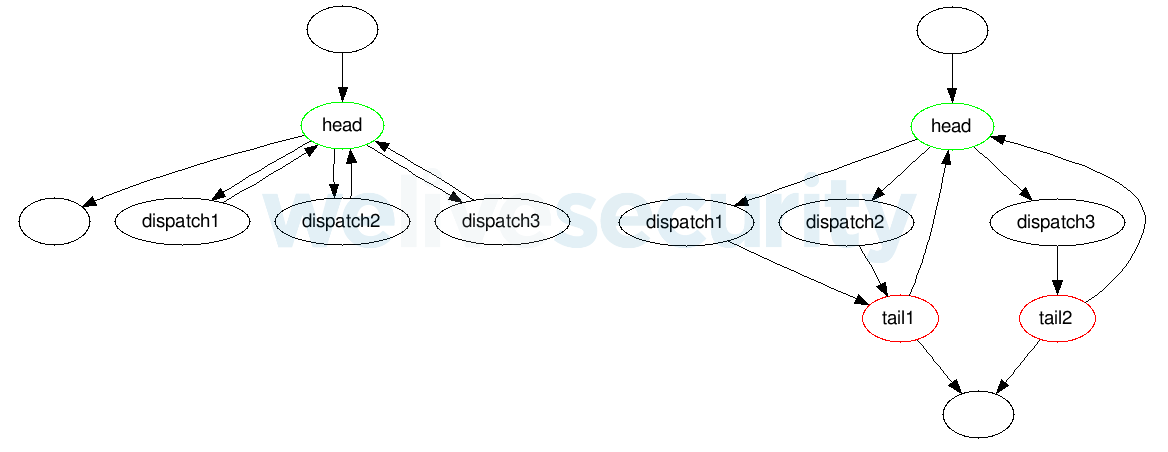
Figure 6. Structure d'une boucle d'aplanissement sans queue (à gauche) et avec plusieurs queues (à droite)
- La tête ne contient pas de table de saut tout de suite. Au lieu de cela, il peut y avoir plusieurs tables de saut et il y a une séquence de branches, avant les tables de saut, en recherchant de façon binaire la bonne répartition.
- La valeur de la variable de contrôle peut être utilisée à l'intérieur des envois ; cela signifie que la valeur de contrôle doit être conservée/calculée même dans le code désobstrué.
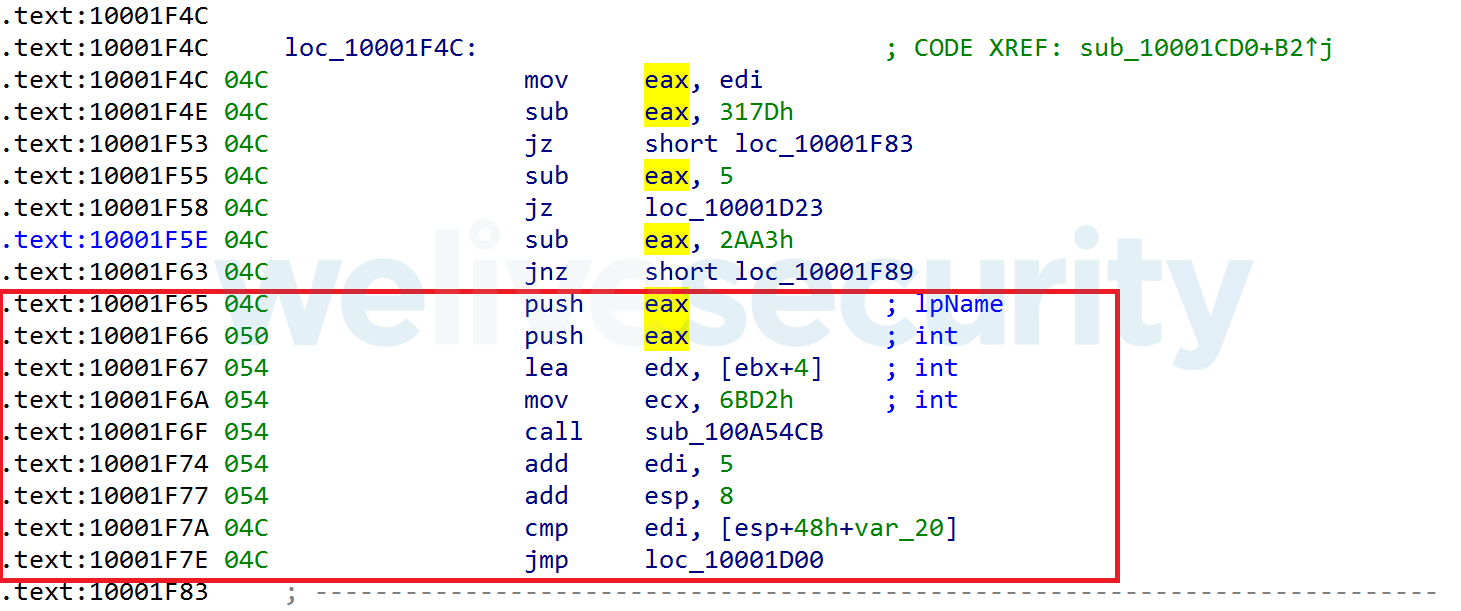
Figure 7. Le registre EDIcontient la variable de contrôle qui est transmise à EAX et utilisée dans l'envoi. L'envoi est surligné en rouge.
- Dans certains cas, la queue contient des instructions qui sont cruciales pour restaurer les valeurs correctes des registres et des variables locales. Lors de la désobfuscation, nous supprimons la queue, nous devons donc nous assurer que ces instructions sont exécutées après chaque envoi, même si elles n'en font pas partie.
- Il y a des cas où il n'y a pas de répartition où l'ID est égal à la valeur actuelle de la variable de contrôle, à ce moment-là.
Désobfuscation
Notre objectif est de construire une fonction de désobfuscation capable de réarranger le code au niveau binaire pour le rendre facilement lisible pour un ingénieur en chef, tout en gardant le code résultant exécutable. Elle doit être capable de reconnaître tous les blocs de base appartenant à chaque envoi et de les copier et déplacer arbitrairement.
Lors de la manipulation des blocs de base, il faut s'assurer de recalculer correctement les adresses relatives des cibles des branches et les adresses formant des tables de saut légitimes.
Notre solution ne prend pas en compte les déplacements, c'est pourquoi il faut toujours s'assurer que l'échantillon est chargé à la même adresse de base.
Nous avons utilisé un cadre de rétro-ingénierie qui nous fournit quelques fonctionnalités utiles, telles que la manipulation d'assemblage et un moteur d'exécution symbolique.
Les paramètres de base de la fonction sont les adresses des blocs de contrôle (tête et queue), la plage et le pas de la variable de contrôle, les noms des registres, et les emplacements mémoire contenant la variable de contrôle, les control_locations, et enfin, l'adresse du premier bloc de base suivant la boucle, que nous définissons comme next_block. Il faut évidemment aussi l'adresse de la fonction à désobstruer et l'adresse où la fonction désobstruée doit être placée.
Nous nous attendons à de multiples queues en raison de l'anomalie 4 ci-dessus.
La fonction de désobfuscation itère à travers la plage de la variable de contrôle par sa valeur de pas pour simuler la boucle réelle de contrôle-débit-aplanissement. À chaque itération, la fonction commence par générer un contexte pour traiter les anomalies 6 et 7. Le contexte doit être placé avant l'envoi respectif.
Le contexte est un bloc de base contenant des instructions attribuant des registres et des adresses mémoire et tenant à jour les control_locations. Le contexte de la première itération ne fait que préserver la valeur de la variable de contrôle. (Notez qu'aucun contexte n'est nécessaire pour traiter l'anomalie numéro 4).
Les derniers blocs de base de la dépêche précédente (ou, dans le cas de la première dépêche, les blocs de base juste avant la tête) sont redirigés vers le contexte créé.
Le bloc de base initial d'un envoi qui doit être exécuté (dans chacune des itérations) est déterminé par la valeur actuelle de la variable de contrôle (ID de l'envoi).
Le bloc de base réel est trouvé en exécutant symboliquement l'algorithme de recherche binaire, qui recherche un bloc de base avec l'ID actuel. L'état initial de l'exécution symbolique contient des control_locations affectées à la valeur actuelle de la variable de contrôle.
Nous arrêtons l'exécution symbolique au premier bloc de base qui (i) contient une branche inconditionnelle, ou, (ii) a une destination qui ne peut pas être déterminée par la variable de contrôle.
On pourrait également émuler cette partie ou utiliser un cadre qui serait capable de simplifier l'algorithme de recherche binaire en une table de saut et de la convertir ensuite en une instruction de commutation à la place. Ces méthodes traitent de l'anomalie 5.
Dans le cas où il n'y a pas d'envoi pour un identifiant particulier, la boucle continue simplement et augmente la variable de contrôle en raison de l'anomalie 8.
L'ensemble de la répartition (c'est-à-dire chaque bloc de base qui est accessible depuis son bloc de base initial jusqu'à sa tête, sa ou ses queues ou son next_block) est alors copiée après le bloc de contexte précédent (comme décrit ci-dessus). Il ne peut pas être simplement déplacé en raison de l'anomalie 2.
Il existe actuellement deux cas peu courants qui peuvent se produire en raison de l'anomalie 3; tous deux entraînent la fin prématurée de l'itération. Ces cas se produisent lorsqu'un envoi :
- Retour de la fonction
- Points vers next_block
Enfin, à la fin de l'itération, les derniers blocs de base de l'expédition précédente (ou les blocs de base juste avant la tête, dans le cas de la première expédition), sont redirigés vers le premier bloc de base en dehors de la boucle d'aplanissement.
Cette méthode résout l'anomalie 1 automatiquement, puisque les envois morts ne seront pas copiés dans le code en résultant.
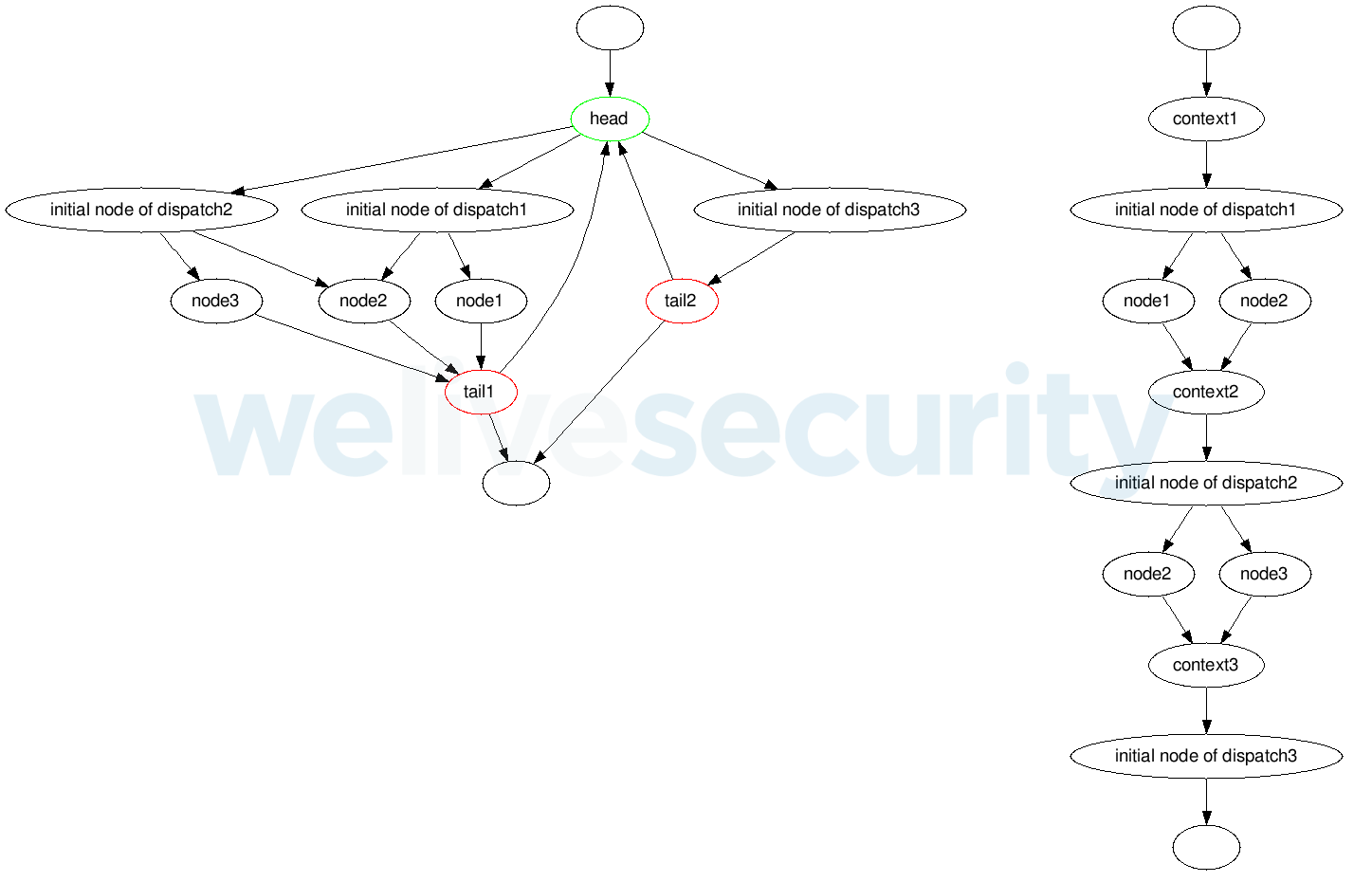
Figure 8. Exemple d'une fonction obfusquée (à gauche) et de sa contrepartie désobfusée (à droite). Les dépêches sont exécutées dans l'ordre suivant : dispatch1 → dispatch2 → dispatch3.
Ces modifications sont ensuite écrites à l'adresse virtuelle où la fonction désobstruée doit être placée.
Dans le cas où nous traitons de l'aplanissement de fonctions fusionnées, nous faisons pointer les références à la fonction cible ayant la même valeur initiale de la variable de contrôle dans le paramètre, vers l'adresse de la nouvelle fonction désobstruée.
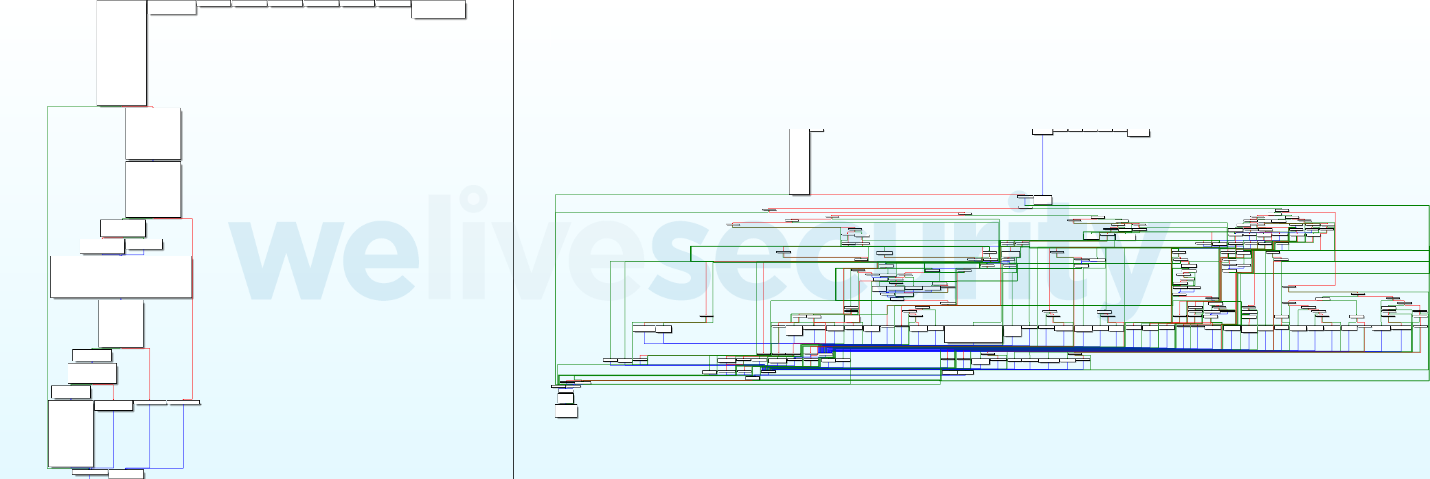
Figure 9. Exemple de graphique de flux de contrôle obfusqué (à droite) et désobfusqué (à gauche)
Améliorations potentielles
L'approche décrite ci-dessus fonctionne exclusivement au niveau de l'assemblage, ce qui n'est pas suffisant pour rendre la désobfuscation entièrement automatisée.
La raison en est que la reconnaissance précise de tous les motifs est assez difficile, principalement en raison des diverses optimisations du compilateur présentes dans les obfuscations au niveau du code source. La reconnaissance des motifs est nécessaire dans notre cas, par exemple, pour remplir automatiquement les paramètres de la fonction de désobfuscation de base.
L'avantage de cette approche est que le code résultant peut effectivement être exécuté immédiatement et que l'on peut utiliser des outils de rétro-ingénierie arbitraires pour une analyse plus approfondie.
Cette approche pourrait être encore améliorée par l'utilisation d'une représentation langage progressive (IR, pour intermediate reprensentation), qui fournit des techniques d'optimisation qui, entre autres, élimineraient la plupart des anomalies générées par les compilateurs, et permettraient ainsi la reconnaissance automatique des paramètres requis par la fonction de désobfuscation.
On pourrait également utiliser le RI sélectionnée à la fois pour la reconnaissance et la désobfuscation dont cette dernière, dans notre cas, consiste à réarranger des blocs de base.
L'inconvénient de cette option est que le code résultant se trouverait également dans l'IR, ce qui signifie que l'analyse consécutive devrait également être effectuée avec l'IR. Le nombre d'outils travaillant avec le RI et leurs fonctionnalités pourraient être assez limités, surtout en ce qui concerne la visualisation. De ce fait, il serait difficile d'analyser un échantillon plus complexe, surtout lorsqu'il y a des couches d'obscurcissement supplémentaires. Nous ne serions pas non plus en mesure d'exécuter le code résultant.
Code mort (death code)
Par « code mort », nous entendons un code qui soit n'est jamais exécuté, soit n'a pas d'impact global sur la fonctionnalité. Le logiciel malveillant contient du code mort principalement dans les boucles aplaties (effectivement supprimées par notre fonction de désobfuscation expliquée ci-dessus), mais il y a aussi, par exemple, des exportations inutilisées et il n'y a aucun moyen de distinguer les exportations inutilisées des exportations légitimes.
Quant au code mort dans la boucle aplatie : pour Stantinko, il se trouve toujours à l'intérieur des envois qui ne sont jamais exécutés. Il peut contenir des parties modifiées de logiciels légitimes tels que WinSpy++ (voir l'exemple ci-dessous) qui ont été obscurcies de la même manière.

Figure 10. Partie désobstruée de code mort à l'intérieur d'une dépêche contenant du code WinSpy++ légitime

Figure 11. La partie équivalente du code (comme dans la figure 10) dans la version officielle de WinSpy++
Code « Ne rien faire »
Même après l'opération de désamorçage, il y a des parties de code qui n'ont aucune utilité, entremêlées avec les lignes du "vrai code". Cela a probablement pour but d'obscurcir encore plus l'analyse ou de contourner la détection comportementale.

Figure 12. Les parties marquées sont du code redondant qui itére à travers les deux premiers noms de volume de disque et ne fait rien avec les valeurs retournées
Comme le code n'est pas beaucoup plus difficile à lire, nous avons décidé de ne prendre aucune mesure et avons analysé le code à ce stade.
En général, pour optimiser ce code « ne rien faire » : il faudrait, par exemple, générer des tranches disjointes contenant tous les appels d'API Windows présents. Le critère de découpage serait constitué de tous les paramètres des appels dans chaque tranche disjointe.
Par la suite, nous exécutons les tranches avec une pile d'appels préparée dans un environnement contrôlé et nous considérons qu'une tranche est fonctionnelle si elle fait au moins une des choses suivantes :
- apporter quelques modifications à l'OS sous-jacent;
- exiger qu'une valeur initiale d'un paramètre de fonction ou d'une variable globale soit connue;
- attribuer une valeur à un paramètre de fonction ou à une variable globale;
- affectent directement le flux de contrôle global de la fonction.
Conclusion
Les criminels à l'origine du botnet Stantinko améliorent et développent constamment de nouveaux modules qui contiennent souvent des techniques non standardisées et intéressantes.
Nous avons déjà décrit leur nouveau module de cryptominage; pour l'analyse fonctionnelle du module, reportez-vous à notre blog de novembre 2019. Ce module présente plusieurs techniques d'obscurcissement visant à protéger contre la détection et à contrecarrer l'analyse. Nous avons analysé les techniques et décrit une approche possible pour désobstruer certaines de ces techniques.
Note : pour les IoC et la liste des techniques mappées à la taxonomie MITRE ATT&CK, nous vous invitons à vous référer à notre précédent article décrivant la fonctionnalité de ce cryptomineur.



