
Cada día nos vemos enfrentados a manejar una gran cantidad de información y tomar decisiones a partir de lo que se pueda extraer. Este proceso puede resultar poco organizado y por lo tanto poco eficiente. OSINT permite agregar un componente de inteligencia para que se pueda obtener algo valioso. En este primer post vamos a describir las generalidades de OSINT.
Durante el día 1 de la #ekoparty2013, dentro de los diferentes workshops que pudimos asistir había uno relacionado con OSINT Open-source intelligence. Aunque el desarrollo del taller se vio afectado por problemas técnicos que impidieron que se vieran muchas de las demostraciones, se plantearon algunos conceptos interesantes sobre los cuales hemos empezado a profundizar un poco y que vale la pena rescatar.
En primera instancia, es importante aclarar que cuando hablamos de fuentes de información pública se abren una cantidad de posibilidades con el uso intensivo de tecnologías de la información. Es así como en esta categoría se pueden encontrar algunas fuentes como:
- Información pública de Fuentes gubernamentales con datos demográficos, datos oficiales de presupuestos y sus aplicaciones, documentación de legislaciones, discursos y en general cualquier tipo de información que publiquen entidades relacionadas con el gobierno.
- Los medios de comunicación como periódicos, revistas y otros que basan su funcionamiento en la web, generan una gran cantidad de información de dominio público.
- Foros, redes sociales, blogs y otras comunidades web dejan pública gran cantidad de información.
Este marco de trabajo con información pública, al igual que cualquier proceso de descubrimiento de conocimiento, plantea un proceso que se puede describir en las siguientes etapas:
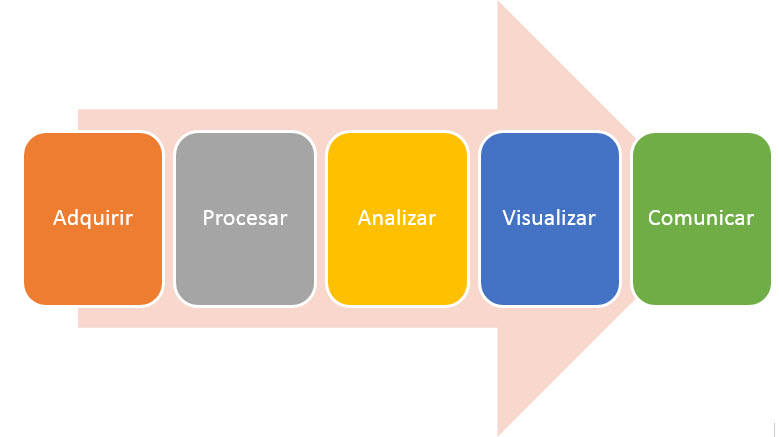
Trabajar con este tipo de información, plantea retos muy importantes al momento de recolectarla y procesarla. Al ser en su mayoría datos no estructurados es necesario contar con herramientas que permitan procesar la información y almacenarla de tal forma que se pueda analizar y extraer conocimiento. Así que son estas dos primeras etapas las que requieren un trabajo más intensivo. La etapa de análisis va a requerir que se utilicen algoritmos específicos de acuerdo al tipo de información que se vaya a analizar. Por ejemplo no es lo mismo hacer un análisis de texto que de una serie temporal de valores de presupuesto.
Las últimas dos etapas, van a permitir que todo el análisis realizado sea realmente valioso para la empresa. Si bien los análisis pueden arrojar resultados interesantes, si no se presentan de forma adecuada no van a generar valor y por lo tanto su comunicación va a ser más complicada.
Desde el punto de vista de la seguridad de la información, la gestión del conocimiento ha adquirido una importancia fundamental al momento de tomar decisiones dentro de cualquier organización. Actualmente, debido a la gran cantidad de información disponible, es muy importante saber cómo gestionarla para aprovechar su análisis y posteriormente tomar las decisiones correctas en cuanto a la solución más adecuada para un problema, o incluso para identificar tendencias o eventos que puedan llegar a afectar la seguridad de la información.
Aunque parezca un poco abstracto este tema, existen herramientas desarrolladas específicamente para modelar esta información pública. Si bien este primer post ha sido más descriptivo, en una próxima publicación estaremos presentando el funcionamiento de algunas herramientas y scripts principalmente utilizando Python tales como recon-ng, OSITN OPSEC Tool o spicymango, que permiten de forma muy sencilla tener modelos que arrojen información valiosa.
H. Camilo Gutiérrez Amaya
Especialista de Awareness & Research



